
To create
a Postgres cache database, you must be connected with a server running
 Postgres (Version
12.0 or above). To connect to a server, click on the Postgres (Version
12.0 or above). To connect to a server, click on the
 button and enter the connection
parameters. If no cache database has been created so far you
get a message that no database is available and will be connected to the default
database postgres. button and enter the connection
parameters. If no cache database has been created so far you
get a message that no database is available and will be connected to the default
database postgres.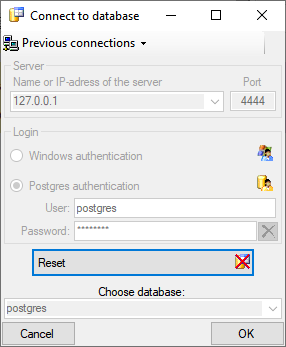 Click on the  button to create a new cache database
(see below). You will be asked for the name of the database and a short
description. button to create a new cache database
(see below). You will be asked for the name of the database and a short
description. After the database was created, you have to update the database to the current version. Click on the Update  button to open a window listing all needed scripts. To run these scripts just
click on the Start update
button. After the update the database is ready to
take your data. Subsequent updates may become necessary with new versions of the
database. For an introduction see a short tutorial
button to open a window listing all needed scripts. To run these scripts just
click on the Start update
button. After the update the database is ready to
take your data. Subsequent updates may become necessary with new versions of the
database. For an introduction see a short tutorial
 . To remove the current database from the server, just click on the . To remove the current database from the server, just click on the
 button. button.In the image on the right you see a screenshot from the tool pgAdmin III. You may use this tool to inspect your data and administrate the database independent from DiversityCollection. Please keep in mind, that any changes you insert on this level may disable your database from being used by DiversityCollection as a sink for your cache data. The data are organized in  schemata, with
public as the default schema. Here you
find schemata, with
public as the default schema. Here you
find
 functions for marking the
database as a module of the Diversity Workbench and the version of the database.
The function highresolutionimagepath translates local image paths into paths for
high resolution images. To use this function it must be adapted to your local
server settings. The tables in this schema are functions for marking the
database as a module of the Diversity Workbench and the version of the database.
The function highresolutionimagepath translates local image paths into paths for
high resolution images. To use this function it must be adapted to your local
server settings. The tables in this schema are  TaxonSynonymy
where the data derived from DiversityTaxonNames are stored and
ScientificTerm where the data derived from DiversityScientificTerms are stored. For every project a
separate schema is created (here
Project_BFLsorbusmmcoll). The project
schemata contain 2
functions for the ID of the
project and the version. The data are stored in the
tables while the packages in their greater
part are realized as TaxonSynonymy
where the data derived from DiversityTaxonNames are stored and
ScientificTerm where the data derived from DiversityScientificTerms are stored. For every project a
separate schema is created (here
Project_BFLsorbusmmcoll). The project
schemata contain 2
functions for the ID of the
project and the version. The data are stored in the
tables while the packages in their greater
part are realized as
 views and
functions extracting and converting the data
from the tables according to their requirements. views and
functions extracting and converting the data
from the tables according to their requirements. |
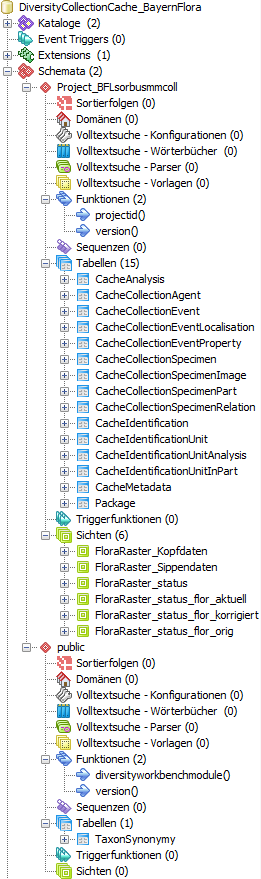
|