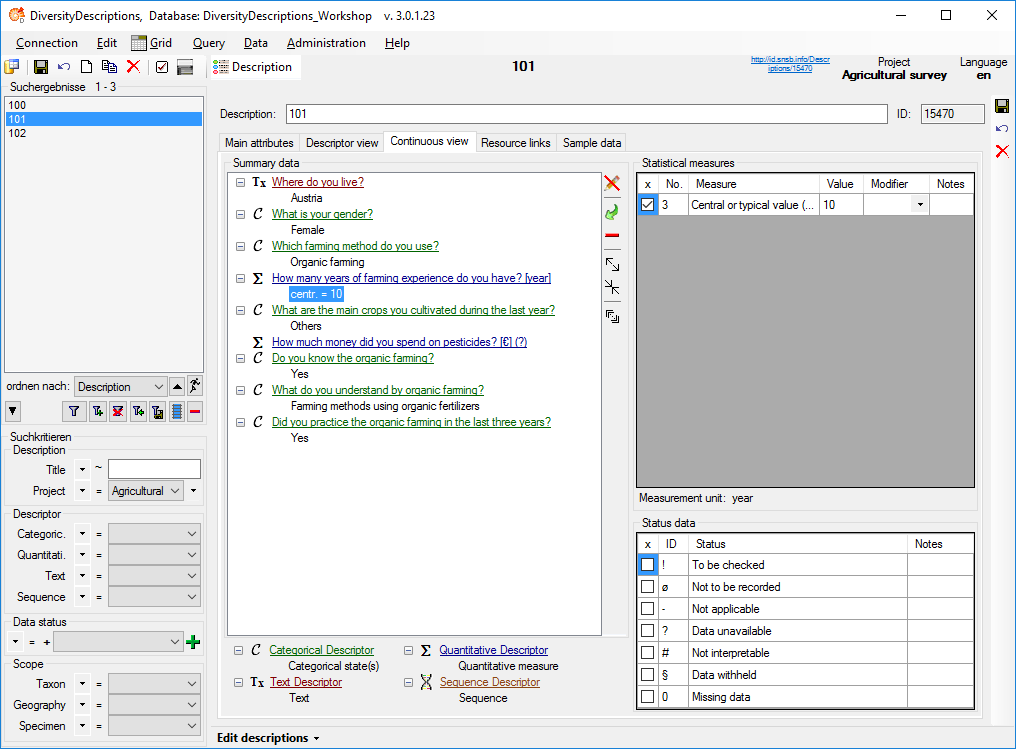
When you close the import wizard and start a query for descriptions of project "Agricultural survey" you will find the three datasets and the imported descriptor data (see image below).
Finnally two more aspects of the imports wizard shall be discussed from a retrospective view. The first one concerns the mapping of external and internal keys and the role of the import session. The second one takes a closer look on the role of the "ID" columns during import.
When opening the import wizard you have to select rsp. create an import session. Imports into Diversity Descriptions usually require at least two import operations, e.g. for descriptors and descriptions. The description data reference descriptors or categorical states. Within the database those relations are built based on numeric values that are provided by the database during creation of the corresponding objects. In the external data files the relations are usually built by numbers coordinated by the user ("QuestionNumber") or by the entity names.
The import session stores the external and internal key
values in separate database tables and therefore builds a bracket around the different
import operations. Each import session is assigned to one project, but for each
project several import sessions may be created. The mapping data may be viewed by
opening the menu item Data ->
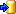 Import ->
Import -> Wizard ->
Wizard ->
 Organize sessions ..., selecting the session and clicking the button
Organize sessions ..., selecting the session and clicking the button
 Mapping (see image below).
Mapping (see image below).
As an addition to the tutorial steps a closer look on
the role of the "ID" fields shall be taken. In principle the most important
IDs during import concern the
 Descriptor ID and the
Categorical state ID during descriptor import. To decide which
file column shall be used for that values during import, it is important to know
how these elements are referenced in the other files.
Descriptor ID and the
Categorical state ID during descriptor import. To decide which
file column shall be used for that values during import, it is important to know
how these elements are referenced in the other files.
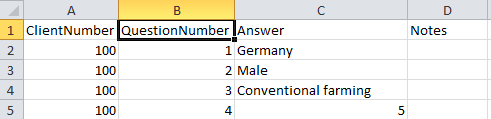
For the descriptor import, you should take a look at the
description data table (see above), which is part of the tutorial example. The descriptor
is referenced by column "QestionNumber", which matches homonymous
column of the descriptor data table (see below). Therefore the natural approach
is to use this column as input for the
Descriptor ID during the descriptor import. Since in most practical
cases the descriptors will have a numbering column, which is used in the referencing
table. Surely more variety exists in the way the categorical states are listed in
the descriptor data file and the way they are referenced by the description data
file.

In the tutorial the first complication is that the possible
states are all concatenated, separated by a semicolon, into a single column of the
descriptor data file. This causes some effort in the transformation, because the
states have to be splitted into the single values. The question is, what is the
Categorical state ID? The answer can be found in the upper table,
because the state name is explicitely mentioned in the description data file as
reference. I.e. for the descriptor import the state name must be used for the
Categorical state ID, too.
In Diversity Descriptions the categorical state names must be unique in relation to their descriptor. But different descriptors may have states with the same names. In our example this situation occures with the two boolean descriptors (states "Yes" and "No") and the state value "Others", wich is used by two descriptors. Therefore it is generally recommended to specify the descriptor for the import of categorical summary data as demonstrated in the tutorial.