Step 4 - Import of categorical states for boolean data
Now we want to import categorical states for the descriptors
specified as "Bool" in the table. In the selection list on the left
side of the window deselect
 Descriptor node,
Descriptor node,
 Rec. stat. measure 1,
Rec. stat. measure 1,
 Rec. modifier 1 and
Rec. frequency 1. Select
Rec. modifier 1 and
Rec. frequency 1. Select
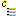 Categorical state 1, click on the
Categorical state 1, click on the
 button to insert a second categorical state and select it, too (see below).
button to insert a second categorical state and select it, too (see below).
In this step we attach two categorical states named "Yes"
and "No" at those descriptors that are marked as "Bool" in file
column "Type". The state values are not present in the "Survey_Questions.txt"
file, but in the "Survey_answers.txt" files we can see the values. In
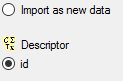
import step
 Attach
at the right side we select
Attach
at the right side we select
 id (see below). It indicates that we do not want to insert new descriptors
but attach data to an existing descriptor.
id (see below). It indicates that we do not want to insert new descriptors
but attach data to an existing descriptor.
Select the import step
 Merge from the list. For
Merge from the list. For
 Descriptor we select the
Attach option because this table shall not be changed, for
Categorical state 1 we select
Descriptor we select the
Attach option because this table shall not be changed, for
Categorical state 1 we select
 Insert, because a new entry shall be inserted (see below).
Insert, because a new entry shall be inserted (see below).

Deselect every column from import step
Descriptor except "id". Mark the "id" column as
 Key column for comparison during attachment
(see below).
Key column for comparison during attachment
(see below).

Inserting the categorical states
In the import step
Categorical state 1 click on
 Categorical state ID and in the center window the assignemt data
for the categorical state id ("id") are displayed. Click on
Categorical state ID and in the center window the assignemt data
for the categorical state id ("id") are displayed. Click on
 to make this the decisive column, further click on
to make this the decisive column, further click on
 From file to select the column "Type" as data source. Now
click on button
From file to select the column "Type" as data source. Now
click on button
 to define a transformation. In the tranformation window click on
to define a transformation. In the tranformation window click on
 to select a filter, then select
Import fixed value and enter the value Yes.
Now click on the
to select a filter, then select
Import fixed value and enter the value Yes.
Now click on the
 button choose column "Type" from the file and enter compare value
Bool (see below).
button choose column "Type" from the file and enter compare value
Bool (see below).
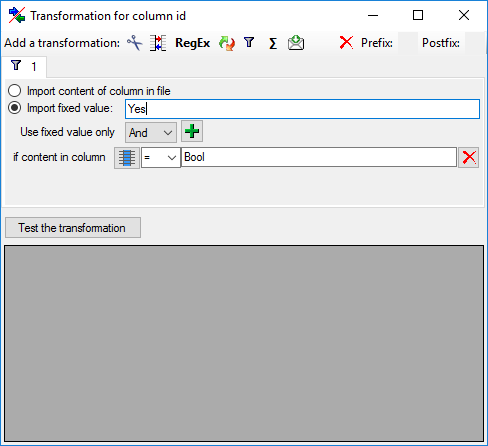
This filter has the following effect: If file column "Type"
contains value "Bool", the value
Yes is provided for import, otherwise the file row will be ignored.
The column now looks as shown below.
Remark: The
Categorical state ID is a number that is generated automatically
from the database when a new categorical state is created. At first sight it seems
confusing that we select a string for this numeric key. The point is that in the
file with the description data the corresponding catogorical state is idenified
by exactly this categorical state name. Since we select this categorical state name
for the
Categorical state ID, the mapping between these two values will
be stored in a separate import mapping table for the actual import session. In the
later import steps this mapping table will allow to find the correct categorical
state.

In the import step
Categorical state 1 click on
 Categorical state name and in the center window the assignemt data
for the categorical state name ("label"), its abbreviation and detailled
description ("abbreviation" and "details") are displayed. Select
"label" and click on
For all: and enter the value Yes.
The column now looks as shown below.
Categorical state name and in the center window the assignemt data
for the categorical state name ("label"), its abbreviation and detailled
description ("abbreviation" and "details") are displayed. Select
"label" and click on
For all: and enter the value Yes.
The column now looks as shown below.

Finally we supply the
 Sequence number. Select
For all: with 1
(see below).
Sequence number. Select
For all: with 1
(see below).

In the import step
Categorical state 2 click on
Categorical state ID and in the center window the assignemt data
for the categorical state id ("id") are displayed. Click on
to make this the decisive column, further click on
From file to select the column "Type" as data source. Now
click on button
to define a transformation. In the tranformation window click on
to select a filter, then select
Import fixed value and enter the value No.
Now click on the
button choose column "Type" from the file and enter compare value
Bool (see below).
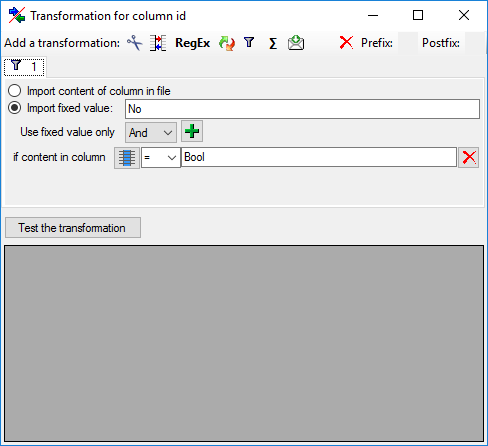
This filter has the following effect: If file column "DataType"
contains value "Bool", the value
No is provided for import, otherwise the file row will be ignored.
The column now looks as shown below.
In the import step
Categorical state 1 click on
Categorical state name and in the center window the assignemt data
for the categorical state name ("label"), its abbreviation and detailled
description ("abbreviation" and "details") are displayed. Select
"label" and click on
For all: and enter the value Yes.
The column now looks as shown below.

Finally we supply the
Sequence number. Select
For all: with "2" (see below).

Testing
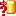
To test if all requirements for the import are met use
the
Testing step. First the test for data
line 2 is shown below, which is an example for a non "Bool" descriptor.
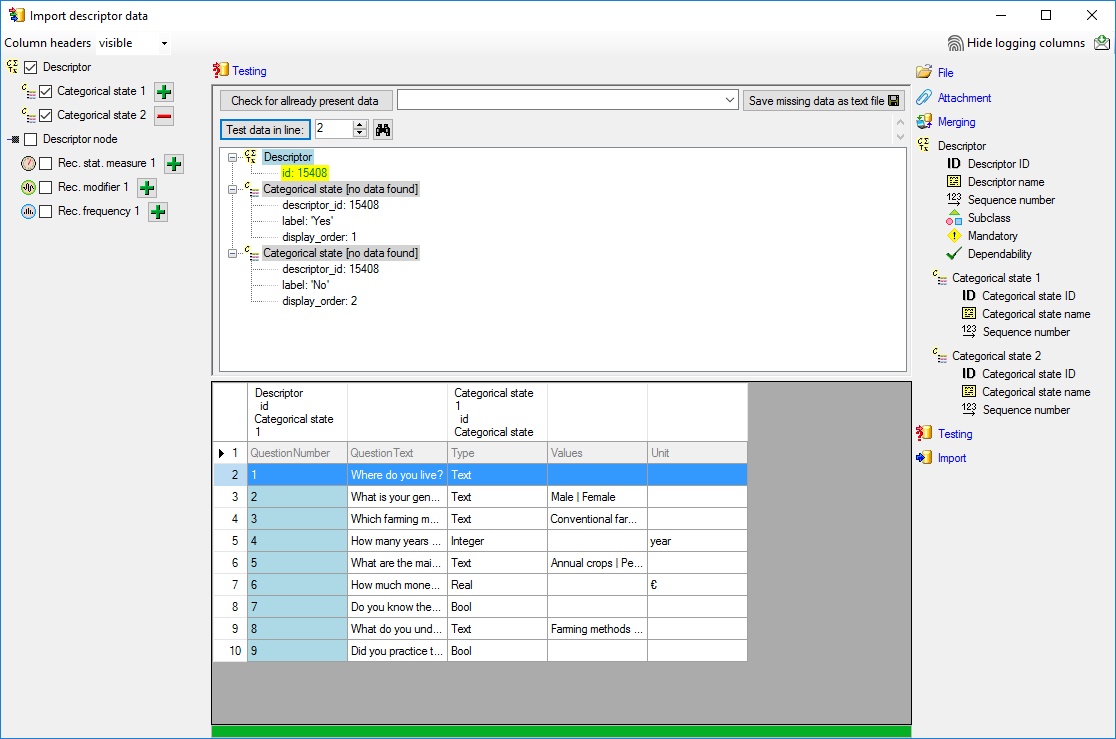
No data shall be inserted. Below the test result for data
line 8, a "Bool" descriptor, is shown.
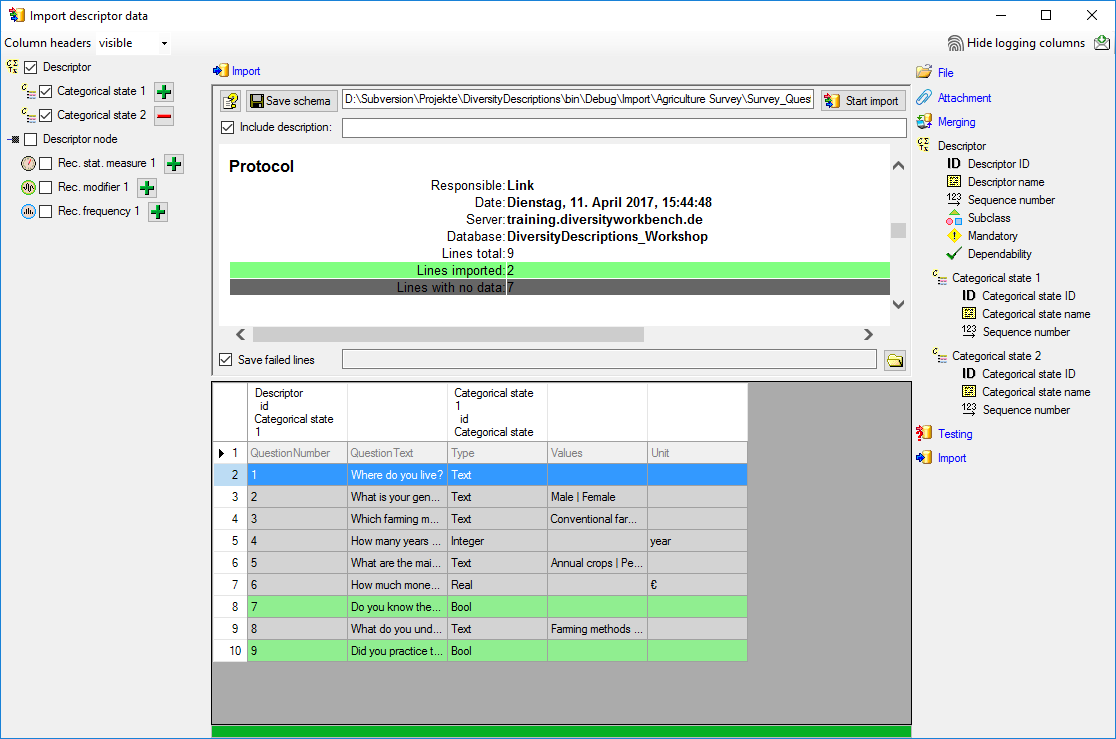
Import
With the last step you can start to import the data into
the database. If you want to repeat the import with the same settings and data of
the same structure, you can save a schema of the current settings. The imported
data lines are marked green, the ignored data lines
grey (see below).
Next: Step
5 - Import of categorical states and update of descriptor