Subsections of Cache Database
Cache Database Basic steps
Basic steps for publication of data via the cache database
1 - Create the cache database
To create a cache database as shown in the chapter Creation of thecache databasee you need to be a system
administrator (s. Login administration).
After this step the cache database should be available and you can
create a Postgres database as final target of your data. To grant access
to the cache database for other users, see chapter Login administrationof the cache databases.
2 - Create a Postgres database
The final formatting of the data e.g. for publication via webservice are
performed in a Postgres database. If no server providing  Postgres is
available, you may install Postgres on your local machine (see
https://www.postgresql.org/ for further information). The creation and
administration of a Postgres database is described in chapter
Administration of the Postgres cache
databasess. To grant access to the Postgres
cache database for other users, see chapter Login administration of thecache databases.
Postgres is
available, you may install Postgres on your local machine (see
https://www.postgresql.org/ for further information). The creation and
administration of a Postgres database is described in chapter
Administration of the Postgres cache
databasess. To grant access to the Postgres
cache database for other users, see chapter Login administration of thecache databases.
3 - Insert sources for taxonomic names, collection specimen, references etc.
This step is optional and depends upon the availability of a source for
e.g. taxonomic names. You may either use sources from your local server
or the public available sources provided by tnt.diversityworkbench.de
(turn to http://www.snsb.info for further information). The needed
settings are described in chapter Sources from othermodules.
4 - Insert a project
The data published in the cache database are organized according to the
projects. Add a  project as shown in chapter Projects
in the cache database. Check the Mapping
of IDs in the source database and make
sure that the data within this project are not withheld from publication
and that the ranges you want to publish are set properly (see chapter
Restrictions for the datatransfer into the cache
database).
project as shown in chapter Projects
in the cache database. Check the Mapping
of IDs in the source database and make
sure that the data within this project are not withheld from publication
and that the ranges you want to publish are set properly (see chapter
Restrictions for the datatransfer into the cache
database).
5 - Transfer the data
The final  transfer of the data is described in chapter Sources forother modules and chapter Transfer of the
data.
transfer of the data is described in chapter Sources forother modules and chapter Transfer of the
data.
6 - Publish or export the data
To  export the data or prepare them for publication according to the
specifications of webservices etc. the data frequently need to be
formatted. This is done with
export the data or prepare them for publication according to the
specifications of webservices etc. the data frequently need to be
formatted. This is done with  packages as described in chapter
Administration of the Packages.
packages as described in chapter
Administration of the Packages.
Cache Database
Create the cache database
To create a cache database you need to be a system administrator (s.
Login administration). To create the cache
database, choose  Data → Cache database
… from the menu. If so far no cache database exists, you will be
asked if a new one should be generated. After the generation of the
cache database a window as shown below will open.
Data → Cache database
… from the menu. If so far no cache database exists, you will be
asked if a new one should be generated. After the generation of the
cache database a window as shown below will open.

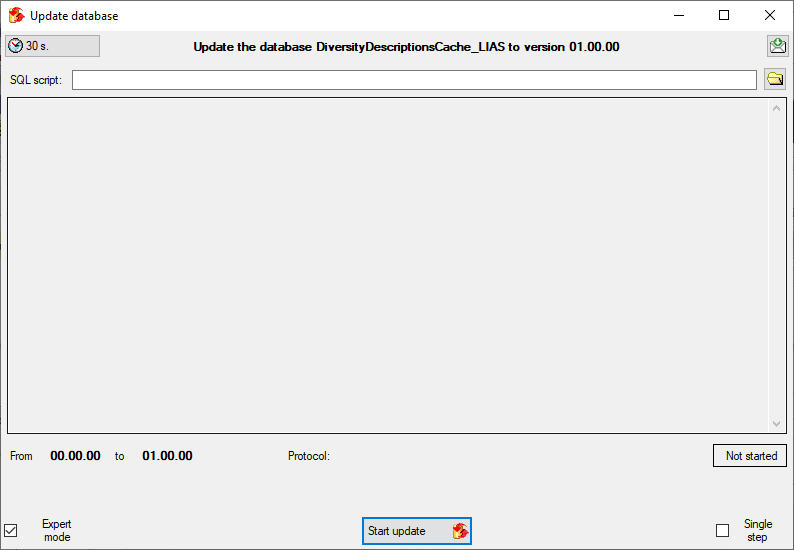
Click on the Update  button to update
the database to the latest version. A window as shown below will open.
Click on Start update to execute all
the scripts needed for the latest version of the database.
button to update
the database to the latest version. A window as shown below will open.
Click on Start update to execute all
the scripts needed for the latest version of the database.
To grant access to the cache database for other users, see chapter
Login administration of the cache databases.
You should now close an re-open the cache database window. During
transfer to the cache database the project metadata are read from a
local Diversity Projects database, if in DiversityDescriptions the
project is linked to it. By default the name of this “project
definitions” database is assumed to be “DiversityProjects” and the same
postfix as the DiversityDescriptions database. If this assumption is not
fulfilled, you will find the button Please check
function ProjectsDatabase (see image below).

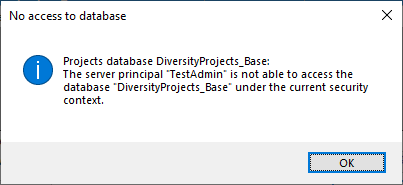
After clicking the button, a message window might inform you about
Projects databases you cannot access due to insufficient access rights
(see image below).
After closing the message window you find all accessible projects
database located on the same database server as your
DiversityDescriptions database (see image below). In columns “Fitting
projects” and “Non fitting projects” you see the number of projects with
fitting rsp. not fitting links to the lsited DiversityProjects database.
Click on the database you want ti use for the cache transfer. If not
fitting projects are present, the button  may be
used to see more details.
may be
used to see more details.
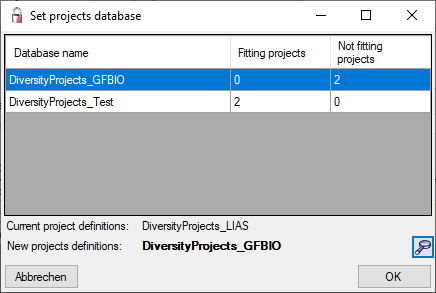
After selecting a database click on button OK.
If there are non fitting links in your projects database, you will find
the button Check missing links for ProjectsDatabase (see image
below). Click this button to view the details. Afterward you will have
get the projects selection window as shown above.

You may now continue with the Administration of the Postgres cachedatabases or insert Sources from other
modules. Anyway, close and re-open the cache
database window before you insert Projects in the cachedatabase.
Cache Database
Id Mapping
Mapping of IDs for the data transfer into the cache database
In the Diversity Descriptions database the main
tables Description,
Descriptor and
CategoricalState have a
numeric “id” as key, which is set by the MS SQL server when the dataset
ist crated. All relations between the tables are set by using these
unique values. For various reasons those internal IDs are not seen as
suitable for all purposes of the cache database. Therefore a mapping of
the internal IDs is performed before the transfer of data to the cache
database.
Default mapping
The default mapping of the IDs is mainly oriented on the way the states
and characters are identified in the widely spread DELTA standard:
- Descriptors are numbered starting with “1” in ascending order and
transferred into the cache database table CacheCharacter. The
order is determined by the descriptor parameter “display_order” and
the alphabetical order. The original “id” is stored as “CharID” in the
target table, the descriptor number as “CID”.
- CategoricalStates are numbered for each character starting with
“1” in ascending order and transferred into the cache database table
CacheState. The order is determined by the categorical state
parameter “display_order” and the alphabetical order. The original
“id” is stored as “StateID” in the target table, the categorical state
number as “CS”.
- Since the categorical state numbers (“CS”) are not unique, each state
is identified, e.g. in a description item, by the character and state
number (“CID”, “CS”).
- Descriptions are numbered starting with “1” in ascending order and
transferred into the cache database table CacheItem. The order is
determined by the alphabetical order. The original “id” is stored as
“ItemID” in the target table, the description number as “IID”. As an
alternative the “IID” may be derived from the field “alternate_id” of
the “Description” table (see following section).
The mapping data are stored related to the project in the tables
CacheMappingDescriptor,
CacheMappingState and
CacheMappingDescription
of the original database.
Mapping adjustment
To set the mapping adjustments, click on the
button (see below).

A window as shown below will open.
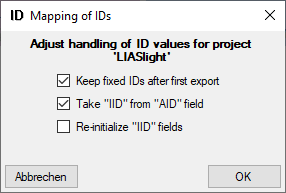
If no option is selected, the default mapping algorithm described
above will be performed for every transfer to the cache database. Any
changes, e.g. insertion of a descriptor or re-arrangement of categorical
states, will affect the “CID”, “CS” and “IID” of the cache database.
If option Keep fixed IDs after first export is selected, the default
mapping algorithm described above will be performed only for the first
transfer to the cache database. Any changes, e.g. insertion of a
descriptor or re-arrangement of categorical states, will NOT affect
the “CID”, “CS” and “IID” of the cache database. New elements will get a
number higher than the last one present. If an element is deleted, this
will result in “missing” numbers in the cache database. Pure
re-arrangements will have no effect.
The last option Take “IID” from “AID” field only affects the
description mapping. By default the descriptions are numbered in
alphabetical order. If this option is chosen, it is tried to use the
field “alternate_id” (“AID” in the GUI) as item number. Preconditions
are that the “AID” is a pure number and that the values are unique. If
the “AID” is not supplied or an alpha-numeric string or if the number is
already occupied, a new ascending value will be set. By using this
option a foreign numbering scheme may be used for the cache database.
When selecting this option you might want select Re-initialize “IID”
fields to build the description mapping at the next cache transfer.
Cache Database
Infrastructure
Infrastructure for the cache database
For the administration of the data that are published via the cache
database, certain tables as shown below are used. These are either
placed in the schema dbo or a schema named according to the
published project, e.g. Project_Test for a project with the name
“Test”. Additionally some basic data are stored in dedicated tables of
the main DiversityDescriptions database.
Tables in the main database
In the main DiversityDescriptions database there is a number of tables
holding the cache database name, information about datawithholding and mapping
information of the IDs. This information
is needed to restore the cache database in case of loss. For the
database diagram take a look at the database section of
this manual.
Central tables in the cache database
There are a number of tables placed in the schema dbo that are
accessible by all projects.
Published project tables
The central published project tables contain the information about the
projects that are published together with the target (Postgres)
databases and the packages including optional add-ons into which they
had been transferred. This information is used to ensure a recovery in
case of a loss of the targets.
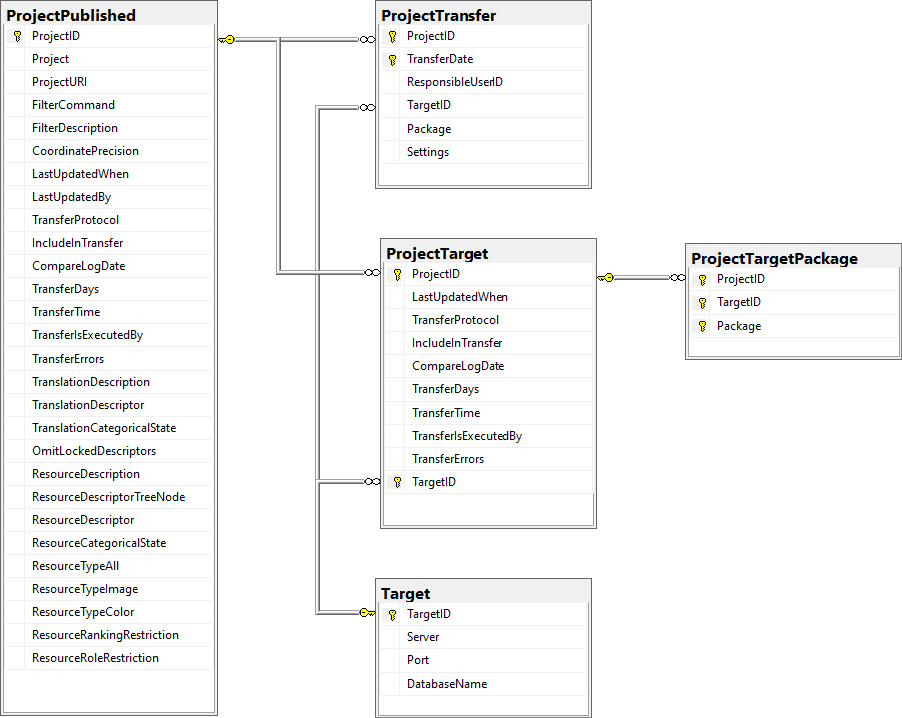
Source tables
To access sources from other modules (e.g. DiversityReferences) there
are tables for the storage of the principal access to the modules and a
number of tables containing the data (depending on the module).
Access tables
These tables contain the principal access like the name of the view
defined to access the data. The example below lists the tables defined
for the module DiversityReferences, but there are corresponding tables
for every module accessed by the cache database.
Data tables
These tables contain the data provided by the module and therefore
depend on the module. The example below lists the tables defined for the
module DiversityReferences, but there are corresponding tables for every
module accessed by the cache database. Since data from various source
databases may be acumulated in the cache database, in general all the
data tables include the BaseURL as part of their keys to ensure
unambiguousness.
To access the data in the source database for the module views are
generated by the client. The name of these views are composed according
to the name of the database and the project to ensure a unique name.
Furthermore letters are appended to identify subordinated tables. These
are stored in the table “<module>Source” and are used by the client
for a transfer of the data from the module database into the tables in
the cache database. The example below lists the view names for the
module DiversityReferences. In this example the source database
“DiversityReferences_Test” and project “DALI” result in the main table
name. By appending “_R” the view name for subordinated table
“ReferenceRelator” is built. This gives the views
References_Test_DALI and References_Test_DALI_R.
Project tables in the cache database
These tables contain the data of the projects with every project having
its own schema. The tables correspond to the tables in the main database
of the module with according the following assignment. In the third
columns the views of the cache database are listed to access the
DiversityDescriptions data. The view access besides the main tables
listed in the second table column and the ID mapping tables. For the
summary data (CacheDescription) additionally subordinated tables,
e.g. Modifier, are accessed to resolve relations in
DiversityDescriptions as simple character strings.
| Table in cache database |
Tables in DiversityDescriptions |
Views in cache database |
| CacheCharacter |
Descriptor |
ViewCacheCharacter |
| CacheCharacterTree |
DescriptorTree |
ViewCacheCharacterTree |
| CacheCharacterTreeNode |
DescriptorTreeNode |
ViewCacheCharacterTreeNode |
| CacheDescription |
CategoricalSummaryData,
QuantitativeSummaryData,
TextDescriptorData,
MolecularSequenceData,
DescriptorStatusData |
ViewCacheCategorical,
ViewCacheQuantitative,
ViewCacheText,
ViewCacheSequence,
ViewCacheStatusData |
| CacheItem |
Description |
ViewCacheItem |
| CacheResource |
Resource,
ResourceVariant |
ViewCacheResourceCharacter,
ViewCacheResourceCharacterTreeNode,
ViewCacheResourceItem,
ViewCacheResourceState |
| CacheScope |
DescriptionScope |
ViewCacheScope |
| CacheState |
CategoricalState |
ViewCacheState,
ViewCacheMeasure |
| CacheTranslation |
Translation |
ViewCacheTranslationCharacter,
ViewCacheTranslationState,
ViewCacheTranslationItem |
Besides the tables mentioned above, the auxilliary tables
ProjectLockedDescriptor and ProjectLockedScope contain the
descriptor IDs and scope types that shall be excluded from the transfer
to the cache database. The auxilliary tables
ProjectPublishedTranslation and ProjectPublishedDescriptorTree
contain language codes of translations (columns label, wording and
detail of source tables Descriptor, CategoricalState and Description)
and the descriptor tree IDs that shall be included in the cache database
transfer. Together with the extended query parameter, which are stored
in the columns FilterCommand and FilterParameter of the table
ProjectPublished, they build the transferrestrictions of the cache database.
Finally, in table CacheMetadata some data from the DiversityProjects
database are stored.
The main tables CacheItem, CacheCharacter and CacheState
have a numeric key (ItemID, CharID and StateID), which is identical to
the unique key in the main database. However, in the cache database the
main adress attributes are IID, CID and CS. CID and SD are in principle
the descriptor and categorical state sequence numbers, where the mapping
algorith guarantees unique ascending values. In this adressing schema a
single state is identified by the combination of CID and CS.
Additionally in table CacheState the recommended statistical
measures of quantitative descriptors are inclueded, where the measure
code (e.g. “Min”, “Max” or “Mean”) is inserted in CS. In table
CacheDescription, which holds the single descriptor or data status
values, the CID and CS are specified for a specific categorical state.
For quantitative data in CS the measurement type is identified by the
measure code. For text and molecular sequence data CS is supplied with
the fixed texts “TE” and “MS”. In case of descriptor status data CS is
set NULL. Instead the data status code is inserted in column Status.
Project procedures for the data transfer into the project tables
For every project table there is a set of procedures that transfers the
data from the main database into the cache table. The names of these
procedures are procPublish + the name of the target table without
“Cache” e.g. procPublishCharacter for the transfer of the data into
the table CacheCharacter. The first steps of the data transfer
perform an update the ID mapping tables in the main database. This is
done in the procedures procPublishMappingItem,
procPublishCharacter and procPublishState, which call dedicated
procedures in the DiversityDescriptions database. As mentioned above,
the original IDs (ItemID, CharID and StateID) are stored together
resulting mapped IDs (IID, CID and CS) in the cache database tables. To
view the mapping information, the views CacheMappingItem,
CacheMappingCharacter and CacheMappingState select the
appropriate values from the cache tables.
List of tables mentioned above
Table ProjectPublished
The projects published via the cache database (Details about the
projects are defined in DiversityProjects)
| ProjectID |
int |
ID of the project to which the specimen
belongs (Projects are defined in DiversityProjects) |
NO |
| Project |
nvarchar (255) |
The name or title of the project as shown in
a user interface (Projects are defined in DiversityProjects) |
YES |
| ProjectURI |
varchar (255) |
The URI of the project, e.g. as provided by
the module DiversityProjects. |
YES |
| FilterCommand |
varchar (MAX) |
The SQL command to select description IDs to
be transferred to the cache database. |
YES |
| FilterDescription |
nvarchar (MAX) |
The XML description of the filter command to
transferred description IDs. |
YES |
| CoordinatePrecision |
tinyint |
Optional reduction of the precision of the
coordinates within the project |
YES |
| LastUpdatedWhen |
datetime |
The date of the last update of the project
data
Default value: getdate() |
YES |
| LastUpdatedBy |
nvarchar (50) |
The user reponsible for the last
update.
Default value: suser_sname() |
YES |
| TransferProtocol |
nvarchar (MAX) |
The protocol created during the transfer of
the data |
YES |
| IncludeInTransfer |
bit |
If the project should be included in a
schedule based data transfer |
YES |
| CompareLogDate |
bit |
If the log dates of the transferred data
should be compared to decide if data are transferred
Default value: (0) |
YES |
| TransferDays |
varchar (7) |
The days the transfer should be done, coded
as integer values with Sunday = 0 up to Saturday = 6
Default value: '0' |
YES |
| TransferTime |
time |
The time when the transfer should be
executed
Default value: '00:00:00.00' |
YES |
| TransferIsExecutedBy |
nvarchar (500) |
If any transfer of the data is active |
YES |
| TransferErrors |
nvarchar (MAX) |
Errors that occurred during the data
transfers |
YES |
| TranslationDescription |
bit |
If the description item translation should be
included in the data transfer
Default value: (1) |
NO |
| TranslationDescriptor |
bit |
If the descriptor translation should be
included in the data transfer
Default value: (1) |
NO |
| TranslationCategoricalState |
bit |
If the categorical state translation should
be included in the data transfer
Default value: (1) |
NO |
| OmitLockedDescriptors |
bit |
If the locked descriptors and their states
shall be omitted in the data transfer
Default value: (0) |
NO |
| ResourceDescription |
bit |
If the description item resources should be
included in the data transfer
Default value: (0) |
NO |
| ResourceDescriptorTreeNode |
bit |
If the descriptor tree node resources should
be included in the data transfer
Default value: (0) |
NO |
| ResourceDescriptor |
bit |
If the descriptor resources should be
included in the data transfer
Default value: (0) |
NO |
| ResourceCategoricalState |
bit |
If the categorical state resources should be
included in the data transfer
Default value: (0) |
NO |
| ResourceTypeAll |
bit |
If all resource types should be included in
the data transfer
Default value: (0) |
NO |
| ResourceTypeImage |
bit |
If the resource type "image" should be
included in the data transfer
Default value: (0) |
NO |
| ResourceTypeColor |
bit |
If the resource type "color" should be
included in the data transfer
Default value: (0) |
NO |
| ResourceRankingRestriction |
tinyint |
The minimum resource ranking (0-10) that
should be included in the data transfer
Default value: (0) |
NO |
| ResourceRoleRestriction |
varchar (255) |
The resource roles that should be included in
the data transfer
Default value: NULL |
YES |
Table ProjectTarget
The targets of the projects, i.e. the Postgres databases
| ProjectID |
int |
ID of the project to which the specimen
belongs (Projects are defined in DiversityProjects) |
NO |
| LastUpdatedWhen |
datetime |
The date of the last update of the project
data |
YES |
| TransferProtocol |
nvarchar (MAX) |
The protocol created during the transfer of
the data |
YES |
| IncludeInTransfer |
bit |
If the project should be included in a
schedule based data transfer
Default value: (1) |
YES |
| CompareLogDate |
bit |
If the log dates of the transferred data
should be compared to decide if data are transferred
Default value: (0) |
YES |
| TransferDays |
varchar (7) |
The days the transfer should be done, coded
as integer values with Sunday = 0 up to Saturday = 6
Default value: (0) |
YES |
| TransferTime |
time |
The time when the transfer should be
executed
Default value: '00:00:00.00' |
YES |
| TransferIsExecutedBy |
nvarchar (500) |
If any transfer of the data is active |
YES |
| TransferErrors |
nvarchar (MAX) |
Errors that occurred during the data
transfers |
YES |
| TargetID |
int |
The ID of the server, relates to table
Target |
NO |
Table ProjectTargetPackage
Packages for projects as documented in the table Package in the Postgres
database
| Column |
Data type |
Description |
Nullable |
| ProjectID |
int |
Refers to ProjectID in table ProjectTarget |
NO |
| TargetID |
int |
Referes to TargetID in table ProjectTarget |
NO |
| Package |
nvarchar (50) |
Package installed for this project target |
NO |
Table ProjectTransfer
The transfers of data of a project
| ProjectID |
int |
ID of the project, part of PK |
NO |
| TransferDate |
datetime |
Date of the transfer. Part of PK
Default value: getdate() |
NO |
| ResponsibleUserID |
int |
The ID of the user as stored in table
UserProxy of the source database, responsible for the transfer
Default value: (-1) |
YES |
| TargetID |
int |
If the transfer regards a postgres database,
the ID of the target (= Postgres database) as stored in table
Target |
YES |
| Package |
nvarchar (50) |
If the transfer regards a package, the name
of the package, otherwise empty |
YES |
| Settings |
nvarchar (MAX) |
The versions, number of transfered data etc.
of the objects concerned by the transfer [format: JSON] |
YES |
Table ReferenceRelator
| Column |
Data type |
Description |
Nullable |
| BaseURL |
varchar (500) |
- |
NO |
| RefID |
int |
- |
NO |
| Role |
nvarchar (3) |
- |
NO |
| Sequence |
int |
- |
NO |
| Name |
nvarchar (255) |
- |
NO |
| AgentURI |
varchar (255) |
- |
YES |
| SortLabel |
nvarchar (255) |
- |
YES |
| Address |
nvarchar (1000) |
- |
YES |
| SourceView |
nvarchar (128) |
- |
NO |
Table ReferenceTitle
| BaseURL |
varchar (500) |
- |
NO |
| RefType |
nvarchar (10) |
- |
NO |
| RefID |
int |
- |
NO |
| ProjectID |
int |
- |
YES |
| RefDescription_Cache |
nvarchar (255) |
- |
NO |
| Title |
nvarchar (4000) |
- |
NO |
| DateYear |
smallint |
- |
YES |
| DateMonth |
smallint |
- |
YES |
| DateDay |
smallint |
- |
YES |
| DateSuppl |
nvarchar (255) |
- |
NO |
| SourceTitle |
nvarchar (4000) |
- |
NO |
| SeriesTitle |
nvarchar (255) |
- |
NO |
| Periodical |
nvarchar (255) |
- |
NO |
| Volume |
nvarchar (255) |
- |
NO |
| Issue |
nvarchar (255) |
- |
NO |
| Pages |
nvarchar (255) |
- |
NO |
| Publisher |
nvarchar (255) |
- |
NO |
| PublPlace |
nvarchar (255) |
- |
NO |
| Edition |
smallint |
- |
YES |
| DateYear2 |
smallint |
- |
YES |
| DateMonth2 |
smallint |
- |
YES |
| DateDay2 |
smallint |
- |
YES |
| DateSuppl2 |
nvarchar (255) |
- |
NO |
| ISSN_ISBN |
nvarchar (18) |
- |
NO |
| Miscellaneous1 |
nvarchar (255) |
- |
NO |
| Miscellaneous2 |
nvarchar (255) |
- |
NO |
| Miscellaneous3 |
nvarchar (255) |
- |
NO |
| UserDef1 |
nvarchar (4000) |
- |
NO |
| UserDef2 |
nvarchar (4000) |
- |
NO |
| UserDef3 |
nvarchar (4000) |
- |
NO |
| UserDef4 |
nvarchar (4000) |
- |
NO |
| UserDef5 |
nvarchar (4000) |
- |
NO |
| WebLinks |
nvarchar (4000) |
- |
NO |
| LinkToPDF |
nvarchar (4000) |
- |
NO |
| LinkToFullText |
nvarchar (4000) |
- |
NO |
| RelatedLinks |
nvarchar (4000) |
- |
NO |
| LinkToImages |
nvarchar (4000) |
- |
NO |
| SourceRefID |
int |
- |
YES |
| Language |
nvarchar (25) |
- |
NO |
| ReplaceWithRefID |
int |
- |
YES |
| CitationText |
nvarchar (1000) |
- |
NO |
| CitationFrom |
nvarchar (255) |
- |
NO |
| LogInsertedWhen |
smalldatetime |
-
Default value: getdate() |
YES |
| SourceView |
nvarchar (128) |
- |
NO |
| ReferenceURI |
varchar (500) |
- |
YES |
| AuthorsCache |
varchar (1000) |
- |
YES |
Table ReferenceTitleSource
| SourceView |
nvarchar (128) |
the name of the view retrieving the data from
the database |
NO |
| Source |
nvarchar (500) |
- |
YES |
| SourceID |
int |
- |
YES |
| LinkedServerName |
nvarchar (500) |
If the source is located on a linked server,
the name of the linked server |
YES |
| DatabaseName |
nvarchar (50) |
The name of the database where the data are
taken from |
YES |
| Subsets |
nvarchar (500) |
Subsets of a source: The names of the tables
included in the transfer separted by "|" |
YES |
| TransferProtocol |
nvarchar (MAX) |
The protocol created during the transfer of
the data |
YES |
| IncludeInTransfer |
bit |
If the source should be included in a
schedule based data transfer |
YES |
| CompareLogDate |
bit |
If the log dates of the transferred data
should be compared to decide if data are transferred
Default value: (0) |
YES |
| TransferDays |
varchar (7) |
The days the transfer should be done, coded
as integer values with Sunday = 0 up to Saturday = 6
Default value: '0' |
YES |
| TransferTime |
time |
The time when the transfer should be
executed
Default value: '00:00:00.00' |
YES |
| TransferIsExecutedBy |
nvarchar (500) |
If any transfer of the data is active |
YES |
| TransferErrors |
nvarchar (MAX) |
Errors that occurred during the data
transfers |
YES |
| LastUpdatedWhen |
datetime |
The date of the last update of the data
Default value: getdate() |
YES |
| LastCheckedWhen |
datetime |
The date and time when the last check for the
need of an update of the content occurred |
YES |
| Version |
int |
-
Default value: (0) |
YES |
Table ReferenceTitleSourceTarget
The targets of the projects, i.e. the Postgres databases
| SourceView |
nvarchar (128) |
SourceView as defined in table
ReferenceSource |
NO |
| Target |
nvarchar (255) |
The targets of the projects, i.e. the
Postgres databases where the data should be transferred to |
NO |
| LastUpdatedWhen |
datetime |
The date of the last update of the project
data
Default value: getdate() |
YES |
| TransferProtocol |
nvarchar (MAX) |
The protocol created during the transfer of
the data |
YES |
| IncludeInTransfer |
bit |
If the project should be included in a
schedule based data transfer
Default value: (1) |
YES |
| CompareLogDate |
bit |
If the log dates of the transferred data
should be compared to decide if data are transferred
Default value: (0) |
YES |
| TransferDays |
varchar (7) |
The days the transfer should be done, coded
as integer values with Sunday = 0 up to Saturday = 6
Default value: (0) |
YES |
| TransferTime |
time |
The time when the transfer should be
executed
Default value: '00:00:00.00' |
YES |
| TransferIsExecutedBy |
nvarchar (500) |
If any transfer of the data is active |
YES |
| TransferErrors |
nvarchar (MAX) |
Errors that occurred during the data
transfers |
YES |
| LastCheckedWhen |
datetime |
The date and time when the last check for the
need of an update of the content occurred |
YES |
Table ReferenceTitleSourceView
| BaseURL |
varchar (500) |
- |
NO |
| RefID |
int |
- |
NO |
| SourceView |
nvarchar (128) |
The name of the source view of the data |
NO |
| LogInsertedWhen |
smalldatetime |
Date and time when record was first entered
(typed or imported) into this system.
Default value: getdate() |
YES |
Table Target
The postgres databases as targets for the data
| Column |
Data type |
Description |
Nullable |
| TargetID |
int |
ID of the target on a postgres server, PK |
NO |
| Server |
nvarchar (255) |
Name of IP of the Server |
NO |
| Port |
smallint |
Port for accessing the server |
NO |
| DatabaseName |
nvarchar (255) |
The name of the database |
NO |
Table CacheCharacter
Character (= descriptors, features) define variables
| CharID |
int |
Database-internal ID of this record (primary
key) |
NO |
| CID |
smallint |
A positive number defining the sequence in
which characters are displayed |
NO |
| CharName |
nvarchar (255) |
Short label (or name) of character |
NO |
| Notes |
nvarchar (MAX) |
Additional detail text explaining or
commenting on the character definition |
YES |
| CharWording |
nvarchar (255) |
Optional separate wording for natural
language generation (CharName will be used if this is missing)
Default value: NULL |
YES |
| Unit |
nvarchar (255) |
A measurement unit (mm, inch, kg, °C, m/s
etc.) or dimensionless scaling factor
Default value: NULL |
YES |
| UnitIsPrefix |
tinyint |
Set to 1 if the measurement unit precedes the
value
Default value: '0' |
NO |
| Subclass |
nvarchar (255) |
The four character subclasses of SDD are all
combined here in one entity and distinguished by this attribute
("categorical", "quantitative", "text" or "sequence")
Default value: 'categorical' |
NO |
| Mandatory |
tinyint |
Is the scoring of this descriptor mandatory
(required) in each item?
Default value: '0' |
NO |
| Exclusive |
tinyint |
Applicable to categorical charactors only. If
usually exclusive = 1, then by default the user interface allows only
entering one state. Nevertheless, multiple states in the data are
valid.
Default value: '0' |
NO |
| ValuesAreInteger |
tinyint |
Set to 1 if the values are integer
Default value: '0' |
NO |
| Reliability |
tinyint |
How reliable and consistent are repeated
measurements or scorings of the character by different observers and on
different objects? (0-10)
Default value: '5' |
NO |
| Availability |
tinyint |
How available is the character or concept for
identification? (0-10)
Default value: '5' |
NO |
| SequenceType |
nvarchar (255) |
Type of molecular sequence, "Nucleotide" or
"Protein". The value "Nucleotide" covers RNA and DNA sequences
Default value: 'Nucleotide' |
NO |
| SymbolLength |
tinyint |
The number of letters in each symbol.
Nucleotides are always codes with 1-letter symbols, but proteins may use
1 or 3-letter codes (e.g. A or Ala for alanine)
Default value: '1' |
NO |
| GapSymbol |
nvarchar (3) |
A string identifying the "gap" symbol used in
aligned sequences. The gap symbol must always be symbol_length
long
Default value: NULL |
YES |
| NumStates |
smallint |
A positive number specifying the number of
states for this character
Default value: '0' |
NO |
| StateCollection |
nvarchar (255) |
Handling of multiple values: OrSet/AndSet:
unordered set combined with or/and, OrSeq/AndSeq: ordered sequence
combined with or/and, WithSeq: example is “green with brown”, Between:
an example is “oval to elliptic”
Default value: 'OrSet' |
NO |
| Order |
int |
Display order
Default value: (0) |
NO |
Table CacheCharacterTree
The descriptor trees
| Column |
Data type |
Description |
Nullable |
| CharTreeID |
int |
Database-internal ID of this record (primary key) |
NO |
| CharTreeName |
nvarchar (255) |
Descriptor tree name |
NO |
Table CacheCharacterTreeNode
The character tree nodes
| CharTreeNodeID |
int |
Database-internal ID of this record (primary
key) |
NO |
| CharTreeID |
int |
Reference to the character tree to which the
node belongs (foreign key) |
NO |
| ParentTreeNodeID |
int |
Reference to the superior character tree node
- NULL if the tree node is on top level (foreign key)
Default value: NULL |
YES |
| CharTreeNodeName |
nvarchar (255) |
Character tree node name - NULL if node
references a character
Default value: NULL |
YES |
| CID |
smallint |
Reference to the character to which the node
belongs - NULL if the tree node is no leaf (foreign key)
Default value: NULL |
YES |
| Order |
int |
Display order
Default value: (0) |
NO |
Table CacheDescription
The description data in the database
| DescrID |
int |
Database-internal ID of this record (primary
key) |
NO |
| IID |
int |
Reference to the description item to which
the data belong |
NO |
| CID |
smallint |
Reference to the character to which the data
belong |
NO |
| CS |
varchar (18) |
Reference to the state to which the data
belong. Null if data status is specified
Default value: NULL |
YES |
| Status |
varchar (16) |
Data status of the character as 16 letter
code. Null if CS is specified
Default value: NULL |
YES |
| Modifier |
nvarchar (255) |
Modifier value of description item. Relevant
for categorical and quantitative charaters
Default value: NULL |
YES |
| Frequency |
nvarchar (255) |
Frequency value of description item. Relevant
for categorical charaters
Default value: NULL |
YES |
| X |
float |
Numeric value of description item. Relevant
for quantitative charaters |
YES |
| TXT |
nvarchar (MAX) |
Text value of description item. Relevant for
text and molecular sequence charaters |
YES |
| Notes |
nvarchar (MAX) |
Additional text explaining or commenting on
the description item. Relevant for all charaters |
YES |
Table CacheItem
The description item in the database
| ItemID |
int |
Database-internal ID of this record (primary
key) |
NO |
| IID |
int |
A positive number defining the sequence in
which items are displayed |
NO |
| ItemName |
nvarchar (255) |
Short label (or name) of description
item |
NO |
| Notes |
nvarchar (MAX) |
Additional detail text explaining or
commenting on the description item definition |
YES |
| ItemWording |
nvarchar (255) |
Optional separate wording for natural
language generation (ItemName will be used if this is missing)
Default value: NULL |
YES |
| Column |
Data type |
Description |
Nullable |
| ProjectID |
int |
- |
NO |
| ProjectTitle |
nvarchar (400) |
- |
YES |
| ProjectTitleCode |
nvarchar (254) |
- |
YES |
| StableIdentifier |
nvarchar (500) |
- |
YES |
| TechnicalContactName |
nvarchar (254) |
- |
YES |
| TechnicalContactEmail |
nvarchar (254) |
- |
YES |
| TechnicalContactPhone |
nvarchar (254) |
- |
YES |
| TechnicalContactAddress |
nvarchar (254) |
- |
YES |
| ContentContactName |
nvarchar (254) |
- |
YES |
| ContentContactEmail |
nvarchar (254) |
- |
YES |
| ContentContactPhone |
nvarchar (254) |
- |
YES |
| ContentContactAddress |
nvarchar (254) |
- |
YES |
| OtherProviderUDDI |
nvarchar (254) |
- |
YES |
| DatasetTitle |
nvarchar (254) |
- |
YES |
| DatasetDetails |
nvarchar (MAX) |
- |
YES |
| DatasetCoverage |
nvarchar (254) |
- |
YES |
| DatasetURI |
nvarchar (254) |
- |
YES |
| DatasetIconURI |
nvarchar (254) |
- |
YES |
| DatasetVersionMajor |
nvarchar (254) |
- |
YES |
| DatasetCreators |
nvarchar (254) |
- |
YES |
| DatasetContributors |
nvarchar (254) |
- |
YES |
| DatasetGUID |
nvarchar (254) |
- |
YES |
| DateCreated |
nvarchar (254) |
- |
YES |
| DateModified |
nvarchar (254) |
- |
YES |
| SourceID |
nvarchar (254) |
- |
YES |
| SourceInstitutionID |
nvarchar (254) |
- |
YES |
| OwnerOrganizationName |
nvarchar (254) |
- |
YES |
| OwnerOrganizationAbbrev |
nvarchar (254) |
- |
YES |
| OwnerContactPerson |
nvarchar (254) |
- |
YES |
| OwnerContactRole |
nvarchar (254) |
- |
YES |
| OwnerAddress |
nvarchar (254) |
- |
YES |
| OwnerTelephone |
nvarchar (254) |
- |
YES |
| OwnerEmail |
nvarchar (254) |
- |
YES |
| OwnerURI |
nvarchar (254) |
- |
YES |
| OwnerLogoURI |
nvarchar (254) |
- |
YES |
| IPRText |
nvarchar (254) |
- |
YES |
| IPRDetails |
nvarchar (254) |
- |
YES |
| IPRURI |
nvarchar (254) |
- |
YES |
| CopyrightText |
nvarchar (254) |
- |
YES |
| CopyrightDetails |
nvarchar (254) |
- |
YES |
| CopyrightURI |
nvarchar (254) |
- |
YES |
| TermsOfUseText |
nvarchar (500) |
- |
YES |
| TermsOfUseDetails |
nvarchar (254) |
- |
YES |
| TermsOfUseURI |
nvarchar (254) |
- |
YES |
| DisclaimersText |
nvarchar (254) |
- |
YES |
| DisclaimersDetails |
nvarchar (254) |
- |
YES |
| DisclaimersURI |
nvarchar (254) |
- |
YES |
| LicenseText |
nvarchar (254) |
- |
YES |
| LicensesDetails |
nvarchar (254) |
- |
YES |
| LicenseURI |
nvarchar (254) |
- |
YES |
| AcknowledgementsText |
nvarchar (254) |
- |
YES |
| AcknowledgementsDetails |
nvarchar (254) |
- |
YES |
| AcknowledgementsURI |
nvarchar (254) |
- |
YES |
| CitationsText |
nvarchar (254) |
- |
YES |
| CitationsDetails |
nvarchar (254) |
- |
YES |
| CitationsURI |
nvarchar (254) |
- |
YES |
| RecordBasis |
nvarchar (254) |
- |
YES |
| KindOfUnit |
nvarchar (254) |
- |
YES |
| HigherTaxonRank |
nvarchar (254) |
- |
YES |
| TaxonomicGroup |
nvarchar (254) |
- |
YES |
| BaseURL |
varchar (254) |
- |
YES |
| RecordURI |
nvarchar (500) |
- |
YES |
| ProjectLanguageCode |
nvarchar (3) |
- |
YES |
Table CacheResource
The available resources
| ResourceID |
int |
Database-internal ID of this record (primary
key) |
NO |
| EntityID |
int |
Database-internal ID of the referenced
record |
NO |
| TargetTable |
nvarchar (255) |
Name of the target table: "State",
"Chararcter", "CharacterTreeNode" or "Item" (primary key) |
NO |
| ResourceName |
nvarchar (255) |
Short label (or name) of resource |
NO |
| Ranking |
smallint |
Ranking of the resource; range: 0 to 10
Default value: NULL |
YES |
| Role |
nvarchar (255) |
Role of the resource ("unknown"=role not
known or not specified; "diagnostic"=optimized for identification;
"iconic"=icon/thumbnail, needs text; "normative"=defines a resource
object; "primary"=display always, informative without text;
"secondary"=display only on request) |
NO |
| IPRText |
nvarchar (255) |
The license text of the resource
Default value: NULL |
YES |
| IPRURI |
nvarchar (255) |
The license URI of the resource
Default value: NULL |
YES |
| MimeType |
nvarchar (255) |
The type of the resource as MIME type like
"image/jpeg"; color as "color/hexrgb"
Default value: NULL |
YES |
| URL |
nvarchar (500) |
The URL of the resource
Default value: NULL |
YES |
| Order |
int |
Display order
Default value: (0) |
NO |
Table CacheScope
The scope of the description
| ScopeId |
int |
Database-internal ID of this record (primary
key) |
NO |
| IID |
int |
Reference to the description item to which
these data belong |
NO |
| ScopeType |
nvarchar (255) |
Scope type ("GeographicArea", "Citation",
"Observation", "Specimen", "TaxonName", "OtherConcept", "Stage", "Part"
or "Sex") |
NO |
| ScopeName |
nvarchar (255) |
Short label (or name) of scope |
NO |
| DwbURI |
nvarchar (500) |
Reference to DiversityWorkbench
component
Default value: NULL |
YES |
Table CacheState
The states available for characters
| StateID |
int |
Database-internal ID of this record (primary
key) |
NO |
| CID |
smallint |
Reference to the character to which the state
belongs (foreign key) |
NO |
| CS |
varchar (18) |
A short string identifying the states in
relation to its character |
NO |
| StateName |
nvarchar (255) |
Short label (or name) of state |
NO |
| Notes |
nvarchar (MAX) |
Additional detail text explaining or
commenting on the state definition |
YES |
| StateWording |
nvarchar (255) |
Optional separate wording for natural
language generation (StateName will be used if this is missing)
Default value: NULL |
YES |
| MinValue |
float |
Applicable to quantitative characters only;
in support of a plausibility check for values. Example: for tree height
this could be 0, i.e. only positive values allowed
Default value: '-1e308' |
NO |
| MaxValue |
float |
Applicable to quantitative characters only;
in support of a plausibility check for values. Example: for tree height
this could be 99
Default value: '1e308' |
NO |
| Order |
int |
Display order
Default value: (0) |
NO |
Table CacheTranslation
The available translations
| Column |
Data type |
Description |
Nullable |
| TranslationID |
int |
Database-internal ID of this record (primary key) |
NO |
| EntityID |
int |
Database-internal ID of the referenced record |
NO |
| LanguageCode |
nvarchar (3) |
Three-character language code of the translation |
NO |
| SourceColumn |
nvarchar (255) |
Name of the original table column |
NO |
| TargetTable |
nvarchar (255) |
Name of the target table: “State”, “Character” or “Item” |
NO |
| Text |
nvarchar (MAX) |
Translated text |
YES |
Table ProjectLockedDescriptor
The descriptors (=characters) that shall not be published
| Column |
Data type |
Description |
Nullable |
| DescriptorID |
int |
Database-internal descriptor ID of descriptive data that shall no be published (primary key) |
NO |
Table ProjectLockedScope
The scope types that shall not be published
| Column |
Data type |
Description |
Nullable |
| ScopeType |
nvarchar (255) |
Scope types that shall not be pulished (primary key) |
NO |
Table ProjectPublishedDescriptorTree
The descriptor tree IDs that shall be published
| Column |
Data type |
Description |
Nullable |
| DescriptorTreeID |
int |
IDs of descriptor trees that shall be published (primary key) |
NO |
Table ProjectPublishedTranslation
The translation languages that shall be published
| Column |
Data type |
Description |
Nullable |
| LanguageCode |
nvarchar (3) |
Three-letter language codes of translations that shall be published (primary key) |
NO |
Cache Database
Logins
Cache database - User administration
There are two roles in the cache database with a general access to the
data: CacheAdmin (for the administration and transfer of the data) and
CacheUser (with read only access). The data in the cache databases are
organized in projects. Therefore for every project you find one
additional role: CacheAdmin_Project_… with the right to transfer of
the corresponding project to the SQL-Server cache database. You find the
project specific roles in the SQL-Server cache database, in the Postgres
database only CachAdmin and CacheUser are available.
To administrate the logins in the SQL-Server
database, go to the  Update and Sources tab
and click on the
Update and Sources tab
and click on the  button of the cache database to open a window as shown below. To
administrate the access for other logins, you have to be a System
administator. For further details please see the chapter about the
login administration for the main database.
button of the cache database to open a window as shown below. To
administrate the access for other logins, you have to be a System
administator. For further details please see the chapter about the
login administration for the main database.
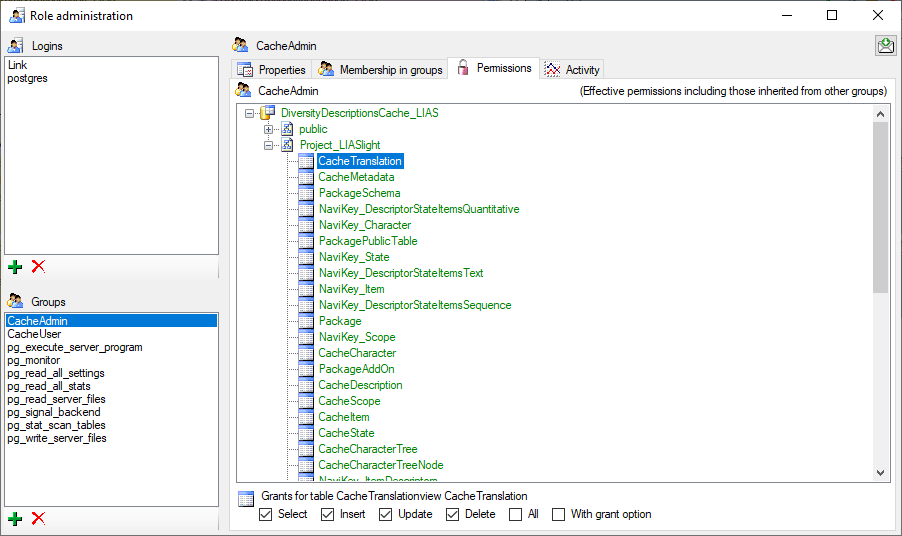
To view the access rights of a selected role click on the
 button to open a window as shown below.
button to open a window as shown below.
Postgres database
To handle the logins and user groups on the Postgres database server, go
to the Update and Sources tab and click on
the button of the postgres database. A window as shown below will
open, where you can create and delete logins and groups. For the logins
you can change their membership in groups and their properties (see
below). On the left you find 2 lists, with the upper list containing the
logins and the list below with the groups resp. roles. For the logins
you can set the general properties as shown below. The login postgres is
created with the installation of the database and is the login for the
administration of the database including the updates etc. For details
about predefined properties like “Is
superuser”, please turn to the Postgresdocumentation.
In the Membership in groups area you can define the groups in which
the login is a member (see below).
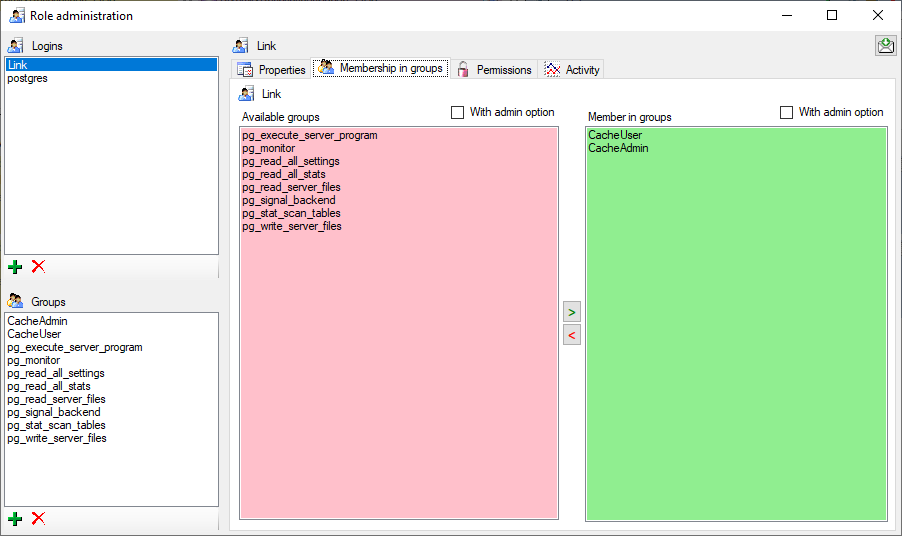
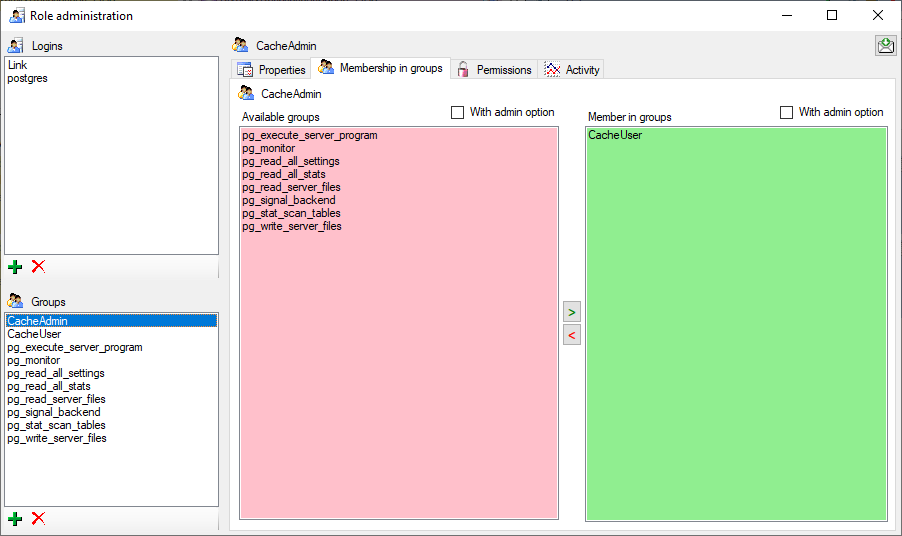
For the groups you can change their membership in other groups and their
permissions (see below).
Cache Database
Packages
Administration of the Packages
The formatting of the data according to the specifications of
webservices etc. is done with packages. There is a growing list of
packages provided with the software. For new packages either turn to the
developers or create a package of your own. The packages are realised as
tables, view, functions etc. reading the data in the tables without any
changes to the data. They therefore can be inserted and removed without
any effects on the original data. The naming of the objects within a
package follow the schema [Name of the package]_… as shown in the
images below.
To administrate the packages installed within one project, click on the
button (see above). A window as shown below will
open listing all available packages.
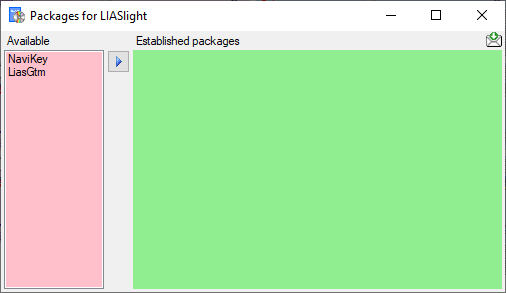
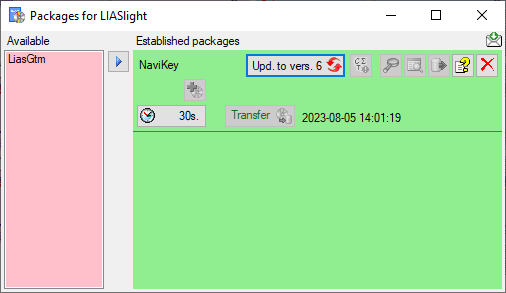
Click on the button to establish the selected
package. To ensure the current version of the package, click on the
Update to vers. … button (see below).
A window will open where all the needed scripts will be listed. For
packages keeping the data in their own tables like NaviKey it may be
necessary to adapt the timeout for database commands. Click on the
 button and enter an appropriate value. For large
amounts of data the value 0 is recommended, which means infinite.
button and enter an appropriate value. For large
amounts of data the value 0 is recommended, which means infinite.
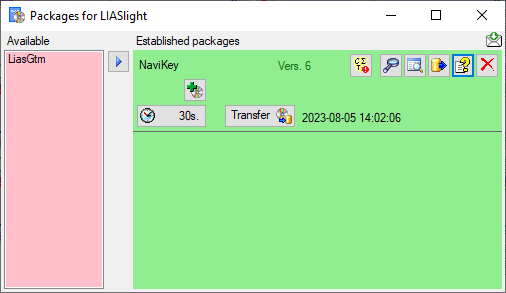
With button  you may select locked characters
to restrict the exported data for the current package. This option might
be useful, if for a certain target, some characters make no sense. E.g.
for the NaviKey application information like the “data record revision”
is irrelevant. For other targets it may be published, because it is no
secret information.
you may select locked characters
to restrict the exported data for the current package. This option might
be useful, if for a certain target, some characters make no sense. E.g.
for the NaviKey application information like the “data record revision”
is irrelevant. For other targets it may be published, because it is no
secret information.
To remove a package use the  delete button and the
delete button and the
 button to get information about the package. For
some packages the button
button to get information about the package. For
some packages the button  indicates that
modified data may be published by using an
Add-On (see below).
indicates that
modified data may be published by using an
Add-On (see below).
A package (e.g. NaviKey) may contain e.g. tables
or materialized views. These need an update after the data have been
transferred to the Postgres database. Click on the
 Transfer button to update the
package data. A window as shown below will open, listing the transfer
steps for the package. Choose the steps that should be transferred and
click on the Start transfer button to transfer
the data.
Transfer button to update the
package data. A window as shown below will open, listing the transfer
steps for the package. Choose the steps that should be transferred and
click on the Start transfer button to transfer
the data.
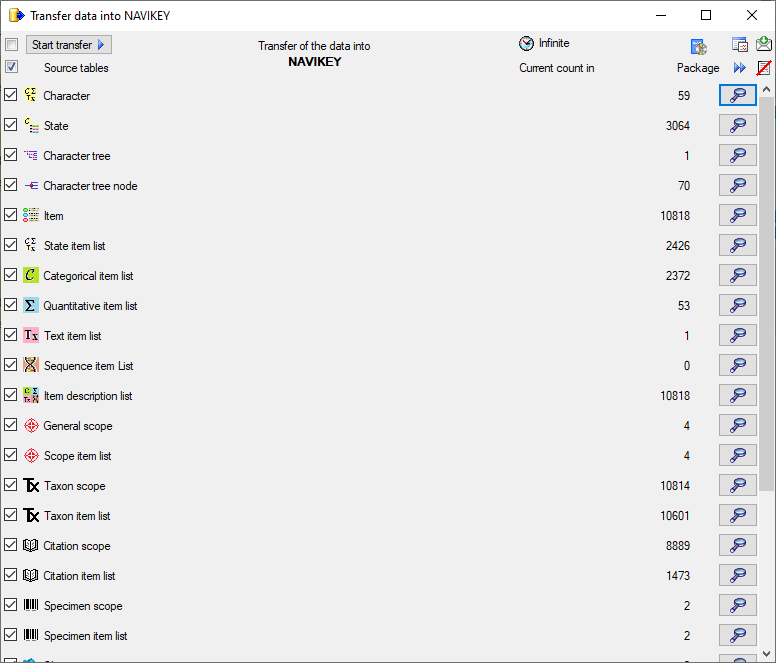
After closing the transfer window you may inspect the data provided by
the package by click on the  button of the
package. Some packages or add-ons may install depend schemas in the
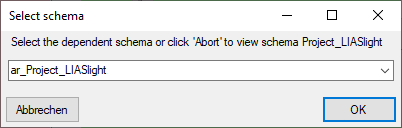
database. In this case you will get a window to select the schema for
display.
button of the
package. Some packages or add-ons may install depend schemas in the
database. In this case you will get a window to select the schema for
display.
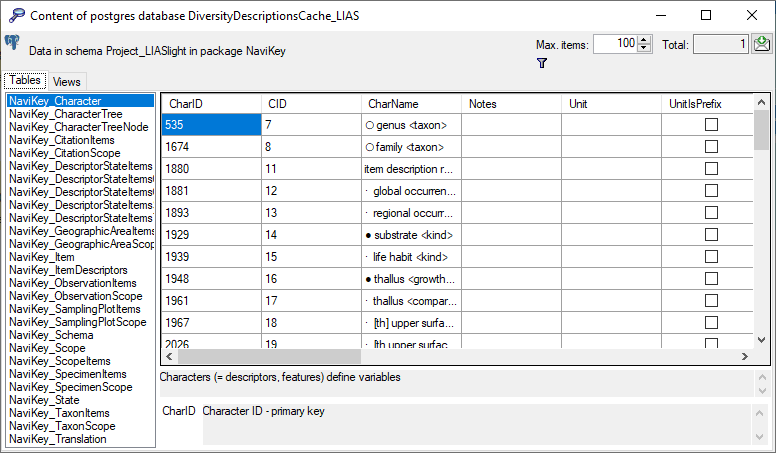
A window as shown below will open listing all package related objects.
For every object (table, view, column, … ) the description is shown in
the lower part of the window.
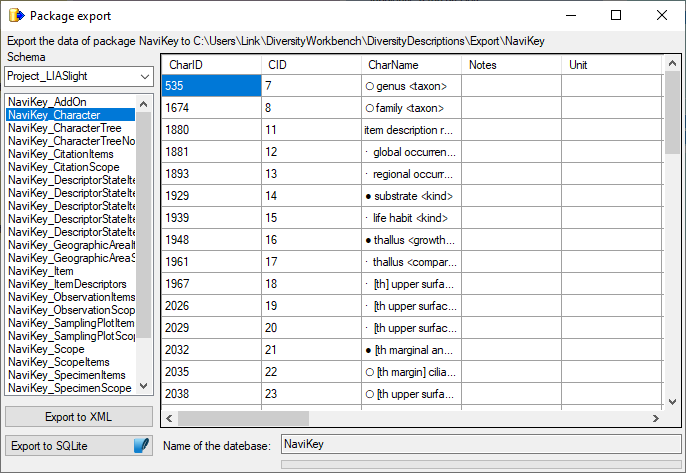
To export the contents of a package, click on the
button. A window as shown below will open listing the main views of the
package. You can export the data as XML (creating a directory with one
xml file for every view) or as  SQLite database
(creating a SQLite database containing the tables).
SQLite database
(creating a SQLite database containing the tables).
Cache Database
Packages Add On
Administration of the Add-Ons for Packages
For certain packages there are add-ons available to adapt a package to
the special specifications of e.g. a project. To add an add-on, click on
the button as shown below. A window as
shown below will open listing all available add-ons.
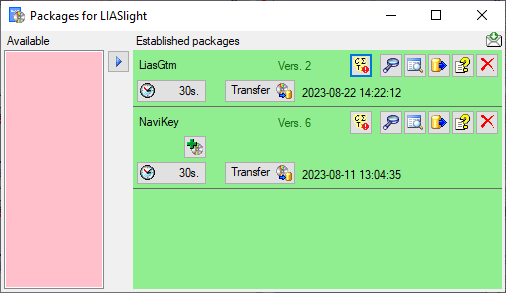
A window as shown below will open listing all available add-ons.
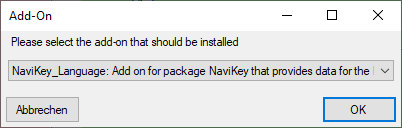
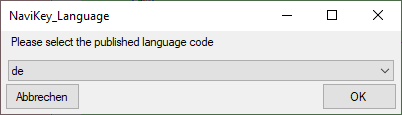
Certain add-ons require the selection of an add-on parameter. E.g. the
Navikey_Language add-on requires the selection of the published
translation language code. In this cases an additional selection window
will be shown (see image below). Remark: Selecting the add-on
parameter and therefore the installation of the add-on might require
that data have been trasferred to the Postgres database before!
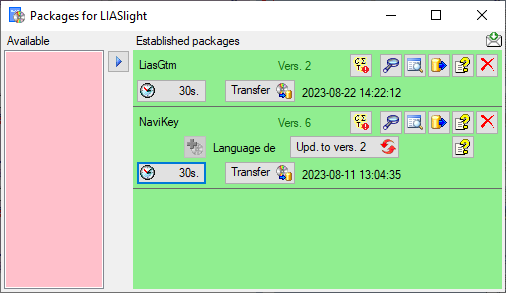
After the add-on has been added, you need to update it to the current
version of the add on with a click on the Upd. to vers. …
button (see below). A window will open where all
the needed scripts will be listed. Some add-ons are exclusive, meaning
that no further add-ons can be added and further updates of the package
are organized via the add-on as shown below. To remove an add-on you
have to remove the package with a click on the
button.
An Add-on defines a version of the package it is compatible with.
Add-ons can not be removed as they perform changes in the package. To
remove an add-on, remove the package and reinstall it. If a package
containing an Add-on needs an update you have to remove the package as
well and reinstall it.
With a click on the first button besides the
package you can generate a description of all objects in the package
(see below).

With a click on the second button besides the
add-on you can view its description (see below).
Cache Database Postgres
Administration of the Postgres cache databases
To
create a Postgres cache database, you must be connected with a server
running .
To connect to a server, click on the  button and enter the connection parameters. If no cache database has
been created so far, you will get a message that no database is
available, otherwise you may select the database as shown below.
button and enter the connection parameters. If no cache database has
been created so far, you will get a message that no database is
available, otherwise you may select the database as shown below.

After entering valid login data to the Postgres server, at least the
 button will be available (see image below).
Click on the button to
create a new cache database (see below). You will be asked for the name
of the database and a short description. button will be available (see image below).
Click on the button to
create a new cache database (see below). You will be asked for the name
of the database and a short description.

After the database was created, you have to update the database to the
current version. Click on the Update  button to open a window listing
all needed scripts. To run these scripts just click on the Start
update
button. After the update the database is ready to take your data.
Subsequent updates may become necessary with new versions of the
database. To remove the current database from the server, just click on
the button to open a window listing
all needed scripts. To run these scripts just click on the Start
update
button. After the update the database is ready to take your data.
Subsequent updates may become necessary with new versions of the
database. To remove the current database from the server, just click on
the  button. button.
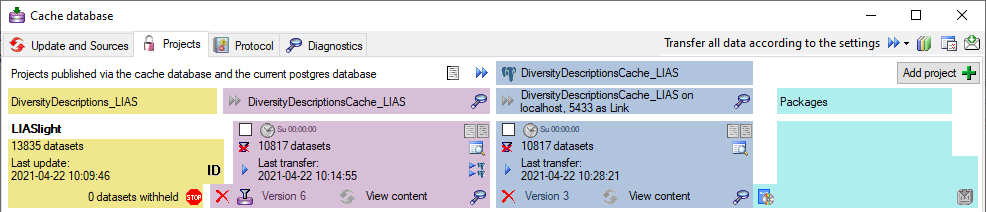
In the image on the right you see a screenshot from the tool pgAdmin 4 . You may use this tool to
inspect your data and administrate the database independent from
DiversityDescriptions. Please keep in mind, that any changes you insert
on this level may disable your database from being used by
DiversityDescriptions as a sink for your cache data. The data are
organized in  schemas, with schemas, with  public as the default schema. Here you find public as the default schema. Here you find
 functions for marking the
database as a module of the Diversity Workbench and the version of the
database. The tables in this schema are e.g. functions for marking the
database as a module of the Diversity Workbench and the version of the
database. The tables in this schema are e.g.  TaxonSynonymy where the data derived from
DiversityTaxonNames are stored and
ReferenceTitle where the data derived from DiversityReferences are
stored. For every project a separate schema is created (here Project_LIASlight). The project schemas
contain 2 functions for the ID
of the project and the version. The data are stored in the tables while the packages in their greater part are
realized as TaxonSynonymy where the data derived from
DiversityTaxonNames are stored and
ReferenceTitle where the data derived from DiversityReferences are
stored. For every project a separate schema is created (here Project_LIASlight). The project schemas
contain 2 functions for the ID
of the project and the version. The data are stored in the tables while the packages in their greater part are
realized as  views and functions extracting and converting
the data from the tables according to their requirements. views and functions extracting and converting
the data from the tables according to their requirements.
If you connect to a Postgres database for the very first time, you must
use an account with sufficient rights to create databases, e.g.
"postgres". After performing the first database update the role
"CacheAdmin" is available, which has sufficient rights for any cache
database operation. To create new logins and grant access to the
Postgres cache database for other users, see chapter Login administration of the cache
databases . |
 |
Cache Database
Postgres Database
Infrastructure for the postgres database
At the PostgreSQL server the tables are either placed in the schema
public or a schema named according to the published project. In
general the tables in postgres have the same strucure as in the
Microsoft SQL cache database, so the transfer to postgres is mainly a
pure copy of their contents. Only some data types are subtituted by
their equivalents in postgres. Therefore you may refer to the cachedatabase documentation concerning
these tables. Some additional tables, views or even schemas and
appropriate transfer functions may be introduced by the
packages and their
add-ons.
In schema public the support functions diversityworkbenchmodule
and version provide the module name “DiversityDescriptionsCache” and
the postgres database version (e.g. “01.00.01”) as strings to support
processing and the database update. In the published project schemas
the support functions projectid and version provide the
corresponding integer values.
All schemas, functions, tables and views are owned by role
CacheAdmin. The additional role CacheUser grants read access to
all elements rsp. execution rights to the support functions.
Source tables
The data tables of the source modules (e.g. DiversityReferences) are
transfered as copies to the schema public. I.e. the access tables
ending with “Source”, “SourceTarget” and “SourceView”, which serve
administrative purposes, are omitted. In the example for the module
DiversityReferences, shown in the databaseinfrastructure page, only the tables
ReferenceTitle and
ReferenceRelator
are tranferred to postgres.
Project tables
The project tables in postgres are simple copies of the cache database
tables. They are placed in a schema named according to the published
project, e.g. Project_Test for a project with the name “Test”. For
details refer to the cache database
documentation:
The view ProjectLanguage provides access to the
ProjectLanguageCode stored in table CacheMetadata. The view
TranlationLanguage provides access to the LanguageCode of
available translations stored in table CacheTranslation.
Packages and Add-Ons
The formatting of the data according to the specifications of
webservices etc. is done with packages. The packages are realized as
tables, views, functions etc. reading the data in the tables without any
changes to the data. They therefore can be inserted and removed without
any effects on the original data. The naming of the objects within a
package follow the schema [Name of the package]_… . Each package
provides a database command file to create the required objects.
Transfer of data is done by calling dedicated transfer functions.
For certain packages there are add-ons available to adapt a package to
the special specifications of e.g. a project. Each add-on provides a
database command file to create the required objects. The traditional
way of realizing an add-on is to modify some transfer functions of the
package. Therefore only one of those add-ons can be installed for a
package. A more flexible approach of handling add-ons is to build a
dedicated add-on transfer function and store its name in the
administration table. For package transfer there a transger step is
defined that reads all associated add-ons from the database and calls
their transfer functions in a defined order. With this approach
insertion of multiple compatible add-ons may be realized.
For the administration of packages and add-ons four tables are used in
the postgres database:
In table Package each installed package, its version and description
are stored. After data transfer to a package transfer date and time are
stored there, too. Add-on data like its version are stored in table
PackageAddOn. Some add-ons may require a parameter that has to be
selected during installation and ist stored in table column
Parameter. If the “non-traditional” approach of realizing add-ons
using dedicated transfer functions is used, this table provides optional
support columns.
The table PackagePublicTable offers support, if a package or add-on
needs to provide data in the schema public. A traditional way to
realize this feature is to mark the package as “using schema public”. As
a consequence the package can only be created in one project of the
whole database. When the package is removed, all objects in schemad
public with the prefix “[Name of the package]_” are dropped.
An alternative is that a package or add-on inserts the public table name
in PackagePublicTable. Furthermore the public table must have a
column where the source schema name is included. If the package is
removed, all entries of the public table with matching package name and
source schema will be deleted. If the public table is empty, the table
itself will be dropped. An example is package NaviKey that enters
all published schemas in the table NaviKey_Schema. This table is
used by the REST service to provide data to the application
DiversityNaviKey.
The table PackageSchema offers support, if a package or add-on needs
to provide data in dependent schemas. For example the add-on
NaviKey_Translations provides access to all available translated
data of the package NaviKey. Therefore for each available language
code a dependent schema named [language code]_Project_[Name of the
project] (e.g. de_Project_LIASlight for the german translation) is
created with views to the data in the master schema. Each dependent
schema is inserted in table PackageSchema (and the public table
NaviKey_Schema for the REST service). When the package is removed, all
dependent schemas will be dropped, too.
Available Packages and Add-Ons
Currently the following packages and add-ons are available:
| Package |
Add-On |
Description |
| LiasGtm |
- |
Tables and views on the data for geographic
visualization of LIAS trait data (https://liasgtm.lias.net/gtm.php) |
| NaviKey |
- |
Tables and views on the data for use with
identification tool DiversityNaviKey
(https://diversityworkbench.net/Portal/DiversityNaviKey) |
| NaviKey |
NaviKey_Wording |
Add on for package NaviKey that provides data for the
DiversityNaviKey application
(https://diversityworkbench.net/Portal/DiversityNaviKey):
(1) For characters/descriptors, categorical states and description items
the wording text is provided instead of the original names. |
| NaviKey |
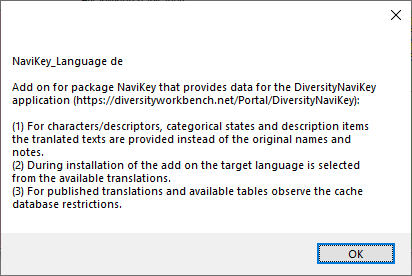
NaviKey_Language |
Add on for package NaviKey that provides data for the
DiversityNaviKey application
(https://diversityworkbench.net/Portal/DiversityNaviKey):
(1) For characters/descriptors, categorical states and description items
the tranlated texts are provided instead of the original names and
notes.
(2) During installation of the add on the target language is selected
from the available translations.
(3) For published translations and available tables observe the cache
database restrictions. |
| NaviKey |
NaviKey_Translations |
Add on for package NaviKey that provides data for the
DiversityNaviKey application
(https://diversityworkbench.net/Portal/DiversityNaviKey):
(1) For characters/descriptors, categorical states and description items
the tranlated texts are provided instead of the original names.
(2) For each available language a schema is created where the data can
be accessed.
(3) The dependent schemas are registered in tables PackageSchema and the
public NaviKey_Schema.
(4) For published translations and available tables observethe cache
database restrictions. |
Tables for Packages and Add-Ons
Table Package
| Column |
Data type |
Description |
Nullable |
| Package |
character varying(50) |
The name of the package |
NO |
| Version |
integer |
The version of the package |
YES |
| Description |
text |
Description of the package |
YES |
| URL |
character varying(500) |
A link to a website with further informations about the package |
YES |
| LogLastTransfer |
timestamp without time zone |
- |
YES |
Table PackageAddOn
| Column |
Data type |
Description |
Nullable |
| Package |
character varying(50) |
The name of the package |
NO |
| AddOn |
character varying(50) |
The name of the package add-on |
NO |
| Parameter |
character varying(50) |
An optional parameter to configure the package add-on |
YES |
| Version |
integer |
The version of the package add-on |
YES |
| TransferFunction |
character varying(50) |
An optional transfer function the package add-on; NULL for exclusive packages |
YES |
| TransferPriority |
integer |
The transfer priority of the package add-on; 0 for exclusive packages |
YES |
Table PackageLockedCharacter
Stores for each schema the CIDs that shall not included in the
package.
| Column |
Data type |
Description |
Nullable |
| Package |
character varying(50) |
The name of the package |
NO |
| CID |
smallint |
The CID that shall not be included in the package |
NO |
Table PackagePublicTable
Stores tables in schema public where data of the package are inserted.
Data in this table are inserted by the package and/or Add-Ons.
| Column |
Data type |
Description |
Nullable |
| Package |
character varying(50) |
The name of the package |
NO |
| Table |
character varying(128) |
The dependent table name in schema public of the package where data of the package are inserted |
NO |
| ControllingSchemaColumn |
character varying(128) |
The column name of dependent table where the controling schema name is stored |
YES |
Table PackageSchema
Stores dependent schemas where data of the package are inserted. Data in
this table are inserted by the package and/or Add-Ons.
| Column |
Data type |
Description |
Nullable |
| Package |
character varying(50) |
The name of the package |
NO |
| Schema |
character varying(128) |
The dependent schema name of the package where data of the package are inserted |
NO |
Cache Database Projects
Projects in the cache database
The data transferred into the
cache database are always transferred according to a project they
belong to. Choose Data → Cache database
… from the menu and select the tab
Projects. If no projects were added so far the window will appear like
shown below.
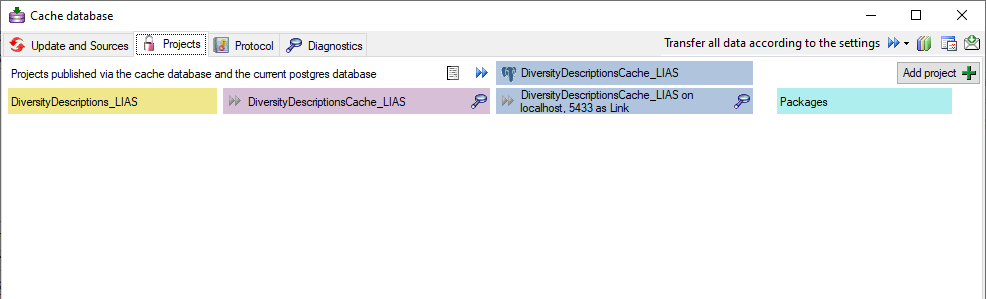
To add a new project for the transfer into the cache database, click on
the Add project  button. In the area below a
new entry as shown below will appear. The area on the right shows the
number of datasets in the project in the source database together with
the date of the last update. To ensure the separation of the data
between the projects, DiversityDescriptions creates a separate schema
for every project named Project_[name of the project] together with
needed roles, tables etc..
button. In the area below a
new entry as shown below will appear. The area on the right shows the
number of datasets in the project in the source database together with
the date of the last update. To ensure the separation of the data
between the projects, DiversityDescriptions creates a separate schema
for every project named Project_[name of the project] together with
needed roles, tables etc..

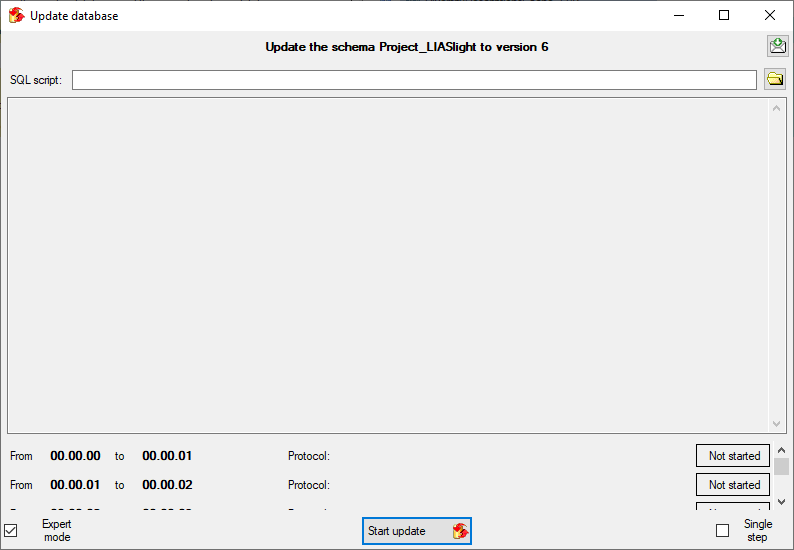
Before transferring data you have to update the project schema to the
latest version, indicated by the appearance of an update button
. Click on the button to open a window as
shown below. Click on the Start update
button to update the schema to the latest version. For adding a project
and performing the database update you need to be a system administrator
(s. Login administration).
After the update the database is ready to transfer data into.
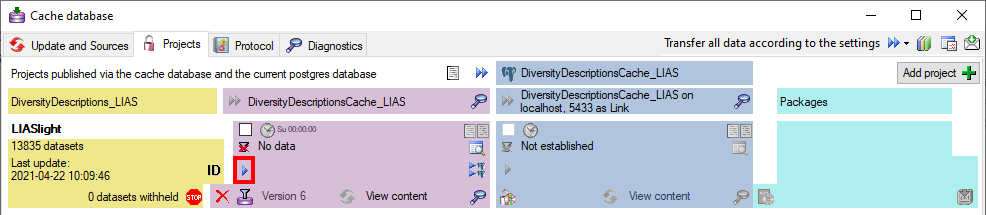
But before starting the cache transfer you should take a look on the
ID mapping, data withholding and data restrictions. The
first two items are stored in the descriptions database, the latter in
the cache database.
With the ID mapping you can determine how
description items, descriptors and categorical states shall be
identified in the cach database and how changes are handled in
subsequent cache transfers. Click on the  button
to edit the ID mapping behaviour for the data of the project (see
below).
button
to edit the ID mapping behaviour for the data of the project (see
below).
If any descriptors are marked with the data status Data withheld, you
have the options to exclude the whole description the export, to hide
only the marked descriptor data or to export the whole dataset. Click on
the  button to edit the data withholding
behaviour for the data of the project (see below).
button to edit the data withholding
behaviour for the data of the project (see below).
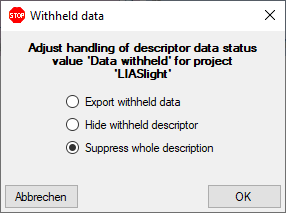
Besides the restrictions in the source database, you can set further
data restrictions for this transfer.
Click on the  button and choose
the data restrictions for the cache transfer (see below).
button and choose
the data restrictions for the cache transfer (see below).
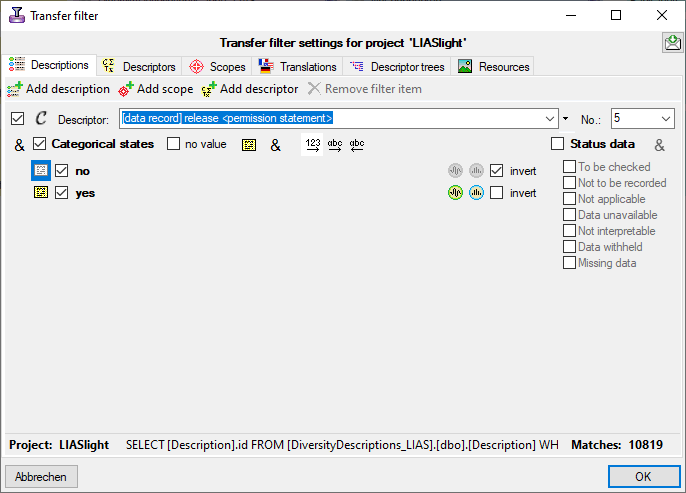
To transfer the data you have 3 options as described in the
Transfer chapter.
Afterwards the number and date of the transferred data are visible as
shown below.

To inspect the transferred data use the View content
button. A window as shown below will open where
all tables containing the data of the project are listed.
Click on the  button to filter the content. A
window as shown below will open. Choose the column for the filter, the
operator (e.g. = ) and the filter value (see below).
button to filter the content. A
window as shown below will open. Choose the column for the filter, the
operator (e.g. = ) and the filter value (see below).
Now click on the  button to add the filter
criteria to the table filter. You may add as many criteria as needed
(see below). With the
button to add the filter
criteria to the table filter. You may add as many criteria as needed
(see below). With the  button you can
clear the filter..
button you can
clear the filter..
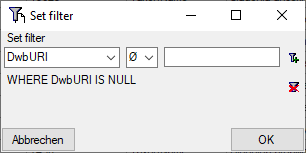
Before you can transfer the data into the Postgresdatabase, you have to connect
 to the Postgres database and click on the
to the Postgres database and click on the
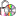 button to establish the project and run
necessary updates . After the project is
established and up to date, use the button to
transfer the data in the Postgres area (see below).
button to establish the project and run
necessary updates . After the project is
established and up to date, use the button to
transfer the data in the Postgres area (see below).

If a project is exported into another Postgres database on the same
server, these databases will be listed underneath the Postgres block
(see image below). For an overview of all target Postgres databases
click on the  button.
button.

If the target is placed on the current server, the text will appear in
black instead of grey (see below). Packages, if administered, will be
listed in the table as well.

In some cases, when a cache database has been deleted on the current
Postgres server, there might still be some administrative information
left. In this case the target is shown in red and you have the option to
delete the administrative data for that target (see below).

In the Postgres database you can
install packages
to adapt the data to any needed format.
Cache Database Restrictions
Restrictions for the data transfer into the cache database
The restrictions of the published data are
defined in the  main database via
projects and data
withholding . In the
cache database further restrictions can be set
for every project. You may set a filter on description data to restrict
the
main database via
projects and data
withholding . In the
cache database further restrictions can be set
for every project. You may set a filter on description data to restrict
the  Descriptions, select the
Descriptions, select the
 Descriptors, the
Descriptors, the  Scopes and the
Scopes and the  Translations that are
transferred.
Translations that are
transferred.
To set the restrictions, click on
the button (see below).
A window as shown in the following sections will open.
Descriptions tab
The Descriptions filter works the same way as
the Extended query. Use buttons
 Add description,
Add description,
 Add scope or
Add scope or
 Add descriptor to insert filter items
for description, scope or descriptor criteria and set the filter
conditions. With button Remove filter item
you may remove the currently selected filter item. In the lower right
corner Matches: shows you the current count of description items
that match the adjusted filter criteria. In the lower center part the
resulting SQL filter is shown.
Add descriptor to insert filter items
for description, scope or descriptor criteria and set the filter
conditions. With button Remove filter item
you may remove the currently selected filter item. In the lower right
corner Matches: shows you the current count of description items
that match the adjusted filter criteria. In the lower center part the
resulting SQL filter is shown.
Descriptors tab
With the Descriptors filter you can select the
descriptors for which summary data shall be transferred. Use button the
arrow buttons << ,
< , > and >> for moving the entries between the Not published and Published list. Click button
Transfer existing to move all descriptors that
are used within the database to the Published list. With button
Transfer from tree you may move all descriptors
connected to the selected Descriptor tree to the Published list. Option Show
sequence numbers includes the descriptor sequence numbers in the
lists. If you do not only want to suppress the descriptive data but also
want to hide the descriptors and their state from the cache database,
select the option Omit descriptors.
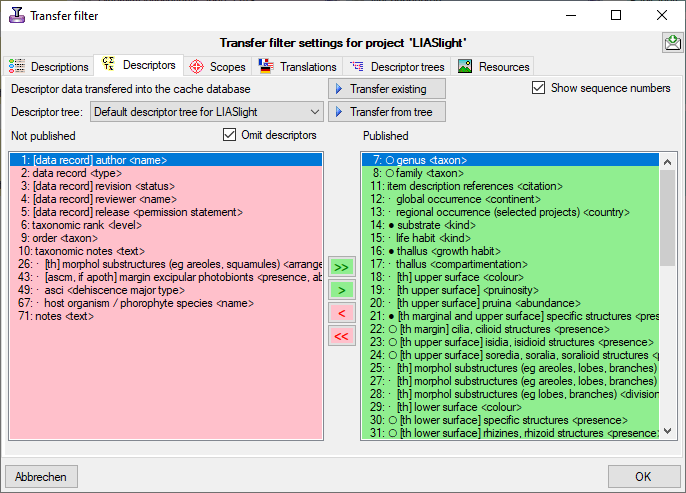
Note: With this option you may keep the selected descriptors
completely away from the cache database. If you want to suppress certain
descriptors only for selected targets, there is an additional
possibility to control the export based on the
Packages (refer to “locked characters”).
Scopes tab
With the Scope filter you can select the scope
type for description scopes that shall be transferred. Use button the
arrow buttons << ,
< , > and >> for moving the entries between the Not published and Published list. Click button
Transfer existing to move all scope types that
are used within the database to the Published list.
Translations tab
With the Translation filter you can
select the translation languages for description items, descriptors and
categorical states that shall be transferred. Use button the arrow
buttons << , <
, > and >> for moving the entries between the Not published and Published list. Click button
Transfer existing to move all translation
languages that are present within the database to the Published list. Use the check
boxes Descriptions, Descriptors and States to select the
tables where translations shall be published. By default, i.e. without
explicit adjustment no tranlations will be transferred to the cache
database.
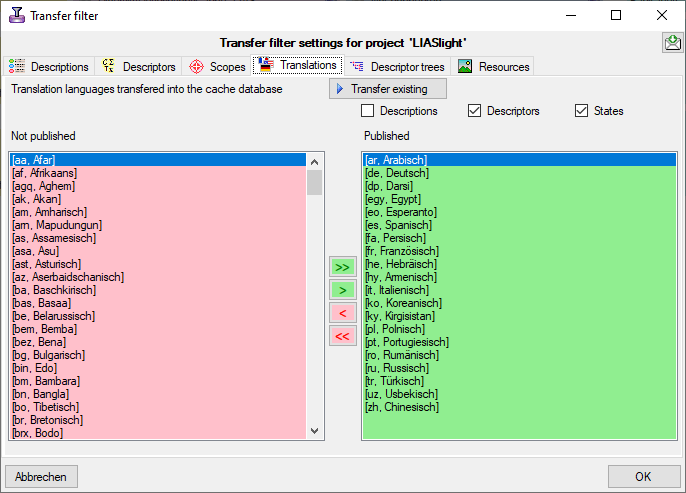
Descriptor trees tab
With the  Descriptor tee filter you can
select the descriptor trees that shall be transferred. Use button the
arrow buttons << ,
< , > and >> for moving the entries between the Not published and Published list. By default,
i.e. without explicit adjustment no descriptor trees will be transferred
to the cache database.
Descriptor tee filter you can
select the descriptor trees that shall be transferred. Use button the
arrow buttons << ,
< , > and >> for moving the entries between the Not published and Published list. By default,
i.e. without explicit adjustment no descriptor trees will be transferred
to the cache database.
Resources tab
With the  Resources filter you can select the
resource links that shall be transferred. You have to select at least
the Entity types and the Resource types that shall be published.
By default, i.e. without explicit adjustment no resources will be
transferred to the cache database.
Resources filter you can select the
resource links that shall be transferred. You have to select at least
the Entity types and the Resource types that shall be published.
By default, i.e. without explicit adjustment no resources will be
transferred to the cache database.
If you select Publish all from section Resource types, all
available resources that either are URLs (starting with “http://” or
“https://”) or color codes (starting with “color://#”) are included in
the transfer. This general restriction ignores resources that are
located on your local machine and therefore not generally reachable. If
you select the explicit types Images or Colors, the resource
variant types must be set correctly, e.g. “image/jpeg”. This can be done
for an individual resource in the corresponding edit panel by retrieving
the media data from the source. A more comfortable way to get those data
for a large amount of resources is to use the database
maintenance tool.
With the check boxes Restrict role you may select role values that
shall be transferred. With Restrict ranking you may select the
minimum ranking value of published resources. If you select the value
“0”, the ranking values will be ignored, i.e. even unranked resources
will be published.
Cache Database Sources
Sources from other modules
To provide details from other modules like DiversityTaxonNames,
DiversityCollection, DiversityReferences etc. in the cached data, this
information is transferred into the cache database together with
the data from DiversityDescriptions database. Use the
button to add a source for the data you need.
You may include data from a local or a linked database. The data for the
cache database are provided via views that will be created for you. With
the  button you can list the sources used in the
projects to get a hint of what may be needed. The tables and view for
the sources are placed in the schema dbo in the
SQL-Server cache database and public in the
Postgres cache databases. In case a new
version for the source is available you get a notation like Needs recreation to
version 2 . In this case you must remove the source with a click
on the button and use the
button to recreate the source. For the inclusion
of sources from services like Catalogue of Life see the chapter
Sources from webservices.
button you can list the sources used in the
projects to get a hint of what may be needed. The tables and view for
the sources are placed in the schema dbo in the
SQL-Server cache database and public in the
Postgres cache databases. In case a new
version for the source is available you get a notation like Needs recreation to
version 2 . In this case you must remove the source with a click
on the button and use the
button to recreate the source. For the inclusion
of sources from services like Catalogue of Life see the chapter
Sources from webservices.
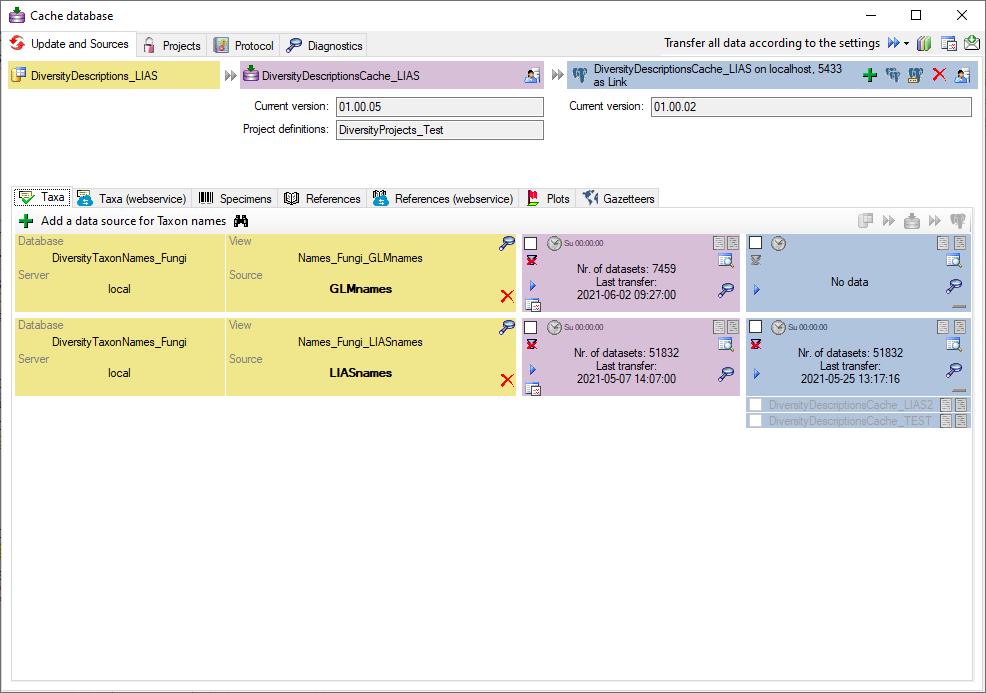
Subsets
The sources of some module provide additional subsets to the main data.
To select the subsets that should be transferred to the cache database,
click on the  button. In the upcoming dialog
(see the example for DiversityTaxonNames below) select those subsets you
want to transfer in addition to the basic name list.
button. In the upcoming dialog
(see the example for DiversityTaxonNames below) select those subsets you
want to transfer in addition to the basic name list.
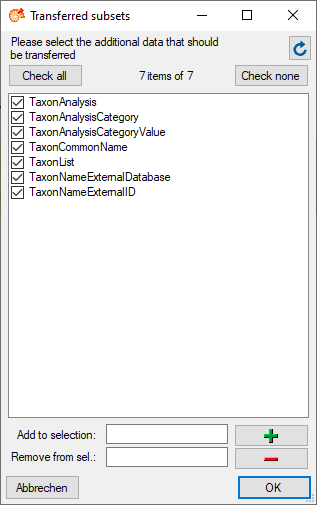
Transfer
Single manual transfer
To transfer the data of a single source into the
cache database use the button and the
buttons to inspect the content.
To transfer the data into the Postgres database, you have to
connect with a database first. Use the button
to transfer the data from the cache database into the
Postgres database. The  button will
transfer the data of all sources in the list into the cache database
(see below).
button will
transfer the data of all sources in the list into the cache database
(see below).
Scheduled transfer
To transfer the data of all sources into the
** **
cache database and all available
Postgres databases, use
the scheduled transfer as backgroundprocess. With this transfer all available
Postgres databases will be included in the data transfer. These targets
are indicated underneath the Postgres block (see image below).

If the target is placed on the current server, the text will appear in
black as shown below.

Removal
With the button you can remove the sources
together with the views (see above).
Orphaned data
In some cases, e.g. if a datasource is removed from the
cache database and there is no active connection to the
Postgres database, the corresponding data will stay in the
postgres database. These orphaned data might disturb subsequent data
transfers, if they overlap with the remaining data. Their source view
and number of datasets are shown in section “Source views not present in
the SQL-Server database” (see below). Click on button
to delete the orphaned data.

Cache Database Transfer
Transfer of the data
To transfer the data you have 3 options:
- Single transfer : Transfer data of a single
project
- Bulk transfer : Transfer data of all
projects and sources selected for the schedule based transfer
With the resp.
button you can decide if the data should
be checked for updates. If this option is active (
) the program will compare the contents and
decide if a transfer is needed. If a transfer is needed, this will be
indicated with a red border of the transfer button
 . If you transferred only a part
of the data this will be indicated by a thin red border for the current
session
. If you transferred only a part
of the data this will be indicated by a thin red border for the current
session  . The context menu of
the button View
differences will show the accession numbers of the datasets with
changes after the last transfer (see below).
. The context menu of
the button View
differences will show the accession numbers of the datasets with
changes after the last transfer (see below).
Competing transfer
If a  competing transfer is active for the same step, this will be
indicated as shown below. While this transfer is active, any further
transfer for this step will be blocked.
competing transfer is active for the same step, this will be
indicated as shown below. While this transfer is active, any further
transfer for this step will be blocked.

If this competing transfer is due to e.g. a crash and is not active any
more, you have to get rid of the block to preceed with the transfer of
the date. To do so you have to reset the status of the transfer. Check
the scheduler  as shown
below. This will activate the button.
as shown
below. This will activate the button.
Now click on the button to open the window for
setting the scheduler options as shown below.
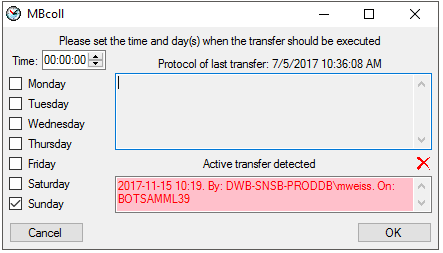
To finally remove the block by the Active
transfer, click on the button. This
will remove the block and you can preceed with the transfer of the data.
Single transfer
To transfer the data for a certain project, click on the
button in the Cache- or Postgres data range (see
below).
A window as shown below will open, where all data ranges for the
transfer will be listed. With the button you can set the timeout for
the transfer of the data where 0 means infinite and is recommended for
large amounts of data. With the 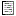 button you can
switch on resp. of the generation of a report. Click on the Start
transfer button to start the transfer.
button you can
switch on resp. of the generation of a report. Click on the Start
transfer button to start the transfer.
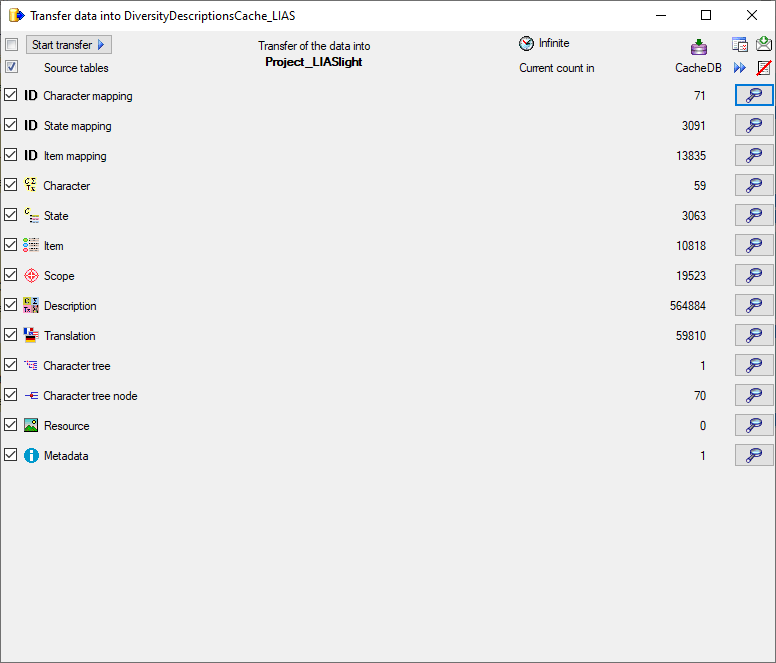
After the data are transferred, the number and data are visible as shown
below.
After the data are transferred successful transfers as indicated by
 an error by
an error by  . The reason for the
failure is shown if you click on the button. For
the transfer to the Postgres database the number in the source and the
target will be listed as shown below indicating deviating numbers of the
data. For the detection of certain errors it may help to activate the
logging as described in the chapter TransferSettings. To inspect the first 100
lines of the transferred data click on the
button.
. The reason for the
failure is shown if you click on the button. For
the transfer to the Postgres database the number in the source and the
target will be listed as shown below indicating deviating numbers of the
data. For the detection of certain errors it may help to activate the
logging as described in the chapter TransferSettings. To inspect the first 100
lines of the transferred data click on the
button.
Bulk transfer
To transfer the data for all projects selected for the schedule based
transfer, click on the button in the cache- or Postgres data range (see
below).
|
|
|
|
|
| DiversityDescriptions_local |
|
DiversityDescriptionsCache_local |
|
DiversityDescriptionsCache_2 on 127.0.0.1, 5555 as postgres |
Together with the transfer of the data, reports will be generated and
stored in the reports directory. Click on the  button in the Timer area to open this directory. To inspect data in the
default schemas (dbo for SQL-Server
button in the Timer area to open this directory. To inspect data in the
default schemas (dbo for SQL-Server  and
public for Postgres ) outside the project
schemata, use the buttons shown in the image
above.
and
public for Postgres ) outside the project
schemata, use the buttons shown in the image
above.
Transfer as background process
Transfer data from database to cache database and all Postgres databases
To transfer the data as a background process use the following
arguments:
- CacheTransfer
- Server of the SQL-server database
- Port of SQL-server
- Database with the source data
- Server for Postgres cache database
- Port for Postgres server
- Name of the Postgres cache database
- Name of Postgres user
- Password of Postgres user
For example:
C:\DiversityWorkbench\DiversityDescriptions> DiversityDescriptions.exe
CacheTransfer snsb.diversityworkbench.de 5432 DiversityDescriptions
127.0.0.1 5555 DiversityDescriptionsCache PostgresUser
myPostgresPassword
The application will transfer the data according to the
settings, generate a protocol as
described above and quit automatically after the transfer of the data.
The user starting the process needs a Windows authentication with access
to the SQL-Server database and proper rights to transfer the data. The
sources and projects within DiversityCollection will be transferred
according to the settings
(inclusion, filter, days and time). The transfer will be documented in
report files. Click on the button to access
these files. For a simulation of this transfer click on the Transfer all data according to the
settings button at the top of the
form. This will ignore the time restrictions as defined in the settings
and will start an immediate transfer of all selected data.
To generate transfer reports and document every step performed by the
software during the transfer of the data use a different first argument:
- CacheTransferWithLogging
- …
C:\DiversityWorkbench\DiversityDescriptions> DiversityDescriptions.exe
CacheTransferWithLogging snsb.diversityworkbench.de 5432
DiversityDescriptions 127.0.0.1 5555 DiversityDescriptionsCache
PostgresUser myPostgresPassword
To transfer only the data from the main database into the cache database
use a different first argument:
To transfer only the data from the cache database into the postgres
database use a different first argument:
The remaining arguments correspond to the list above. The generated
report files are located in the directory …/ReportsCacheDB and the
single steps are witten into the file DiversityCollectionError.log.
History
For every transfer of the data along the pipeline, the settings (e.g.
version of the databases) the number of transferred data and additional
information are stored. Click on the  button
in the respective part to get a list of all previous transfers together
with these data (see below).
button
in the respective part to get a list of all previous transfers together
with these data (see below).
Cache Database
Transfer Protocol
Protocol of the transfers in the cache database
The protocol of any transfer is written into the error log of the
application. To examine the messages of the transfers within the cache
database you may for every single step click on the
button in the transfer window in case an error
occurred. In the main window the protocol for all transfers is shown in
the  Protocol part. Choose Data ->
Cache database … from the menu and select the tab
Protocol. A window will appear like shown
below.
Protocol part. Choose Data ->
Cache database … from the menu and select the tab
Protocol. A window will appear like shown
below.
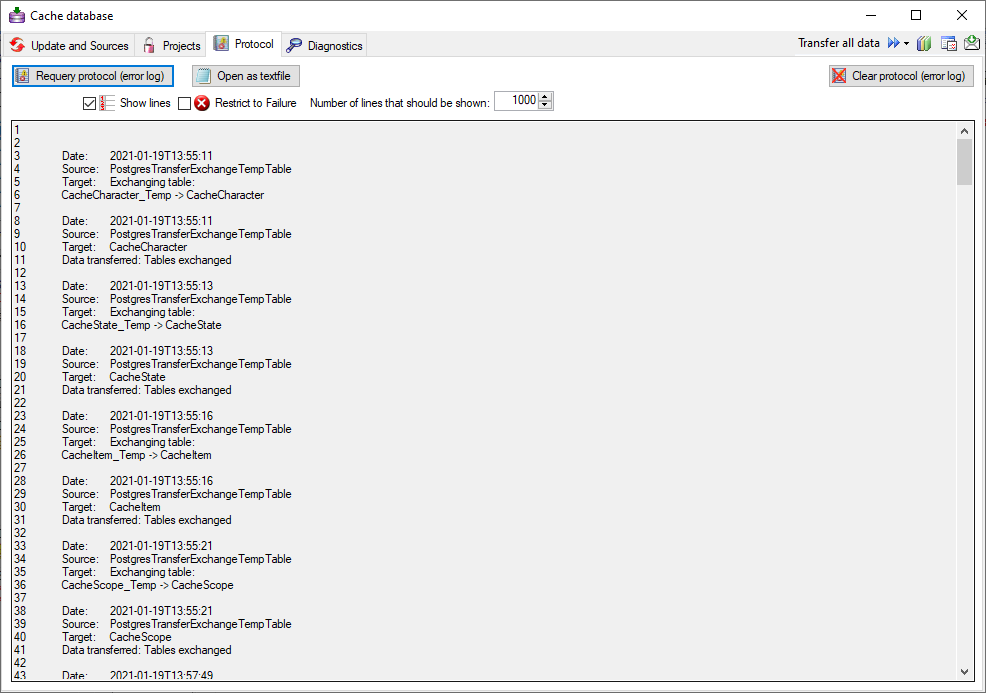
A click on the button Requery protocol (error
log) requeries resp. shows the protocol. The option
 Show lines will show the line numbers of the
protocol and the option Restrict to Failure
will restrict the output to failures and errors stored in the protocol.
By default both options are seleted and the number of lines is
restricted to 1000. In case of longer protocols change the number of
lines for the output. The button
Show lines will show the line numbers of the
protocol and the option Restrict to Failure
will restrict the output to failures and errors stored in the protocol.
By default both options are seleted and the number of lines is
restricted to 1000. In case of longer protocols change the number of
lines for the output. The button  Open as
textfile will show the protocol in the default editor of your
computer. The button
Open as
textfile will show the protocol in the default editor of your
computer. The button  Clear protocol
(error log) will clear the protocol.
Clear protocol
(error log) will clear the protocol.
Cache Database Transfer Settings
Settings for the transfer of the projects in the cache database
To edit the general settings for the transfer, click on the
button in the main form. A window as shown
below will open. Here you can set the timeout
for the transfer in minutes. The value 0 means that no time limit is set
and the program should try infinite to transfer the data. Furthermore
you can set the parameters for the transfer of the data in chunks. If
the amount of data is above a certain threshold, it is faster to divide
the data into smaller chunks. The threshold for transfer into the
cache database and into the
Postgres database can be set as shown below,
together with the maximal size of the chunks. To return to the default
vales click the button Set default values.

Logging
For the detection of certain errors it may help to log the events of the
transfer by activating the logging: 
 →
. The logging is set per
application, not per database. So to detect errors in a transfer started
by a scheduler on a server, you have to activate the logging in the
application started by the server.
→
. The logging is set per
application, not per database. So to detect errors in a transfer started
by a scheduler on a server, you have to activate the logging in the
application started by the server.
Scheduled transfer
The scheduled transfer is meant to be launched on a server on a regular
basis, e.g. once a week, once a day, every hour etc.. The transfer of
the data via the scheduled transfer will take place according to the
settings. This means the program will check if the next planned time for
a data transfer is passed and only than start to transfer the data. To
include a source in the schedule, check the
selector for the scheduler. To set the time and days scheduled for a
transfer, click on the button. A window as
shown below will open where you can select the time and the day(s) of
the week when the transfer should be executed.
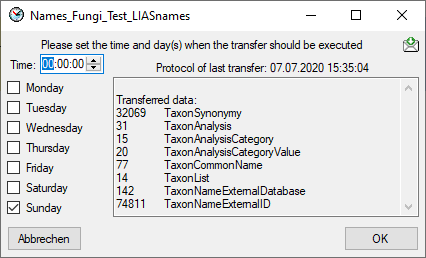
The planned points in time are shown in the form as shown below.

The protocol of the last transfer can be seen as in the window above or
if you click on the button. If an error
occurred this can be inspected with a click no the
 button.
button.
If another transfer on the same source has been started, no further
transfer will be started. In the program this competing transfer is
shown as below.
You can remove this block with a click on the <
button. In opening window (see below) click on the
button. This will as well remove error
messages from previous transfers.
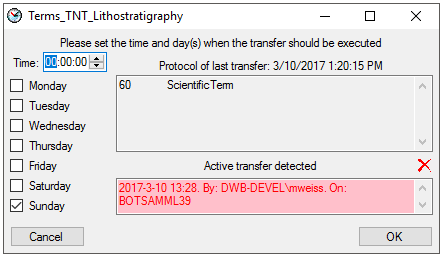
A further option for restriction of the transfers is the comparison of
the date when the last transfer has been executed. Click on the
button to change it to
. In this state the program will compare the
dates of the transfers and execute the transfer only if new data are
available.
Cache Database Webservices
Sources from webservices
To provide details for datasets linked to webservices like Catalogueof Life etc. in the cached data,
this information can be transferred into the cache database together with
the data from the DiversityCollection database. Use the
button to add the webservice you need.
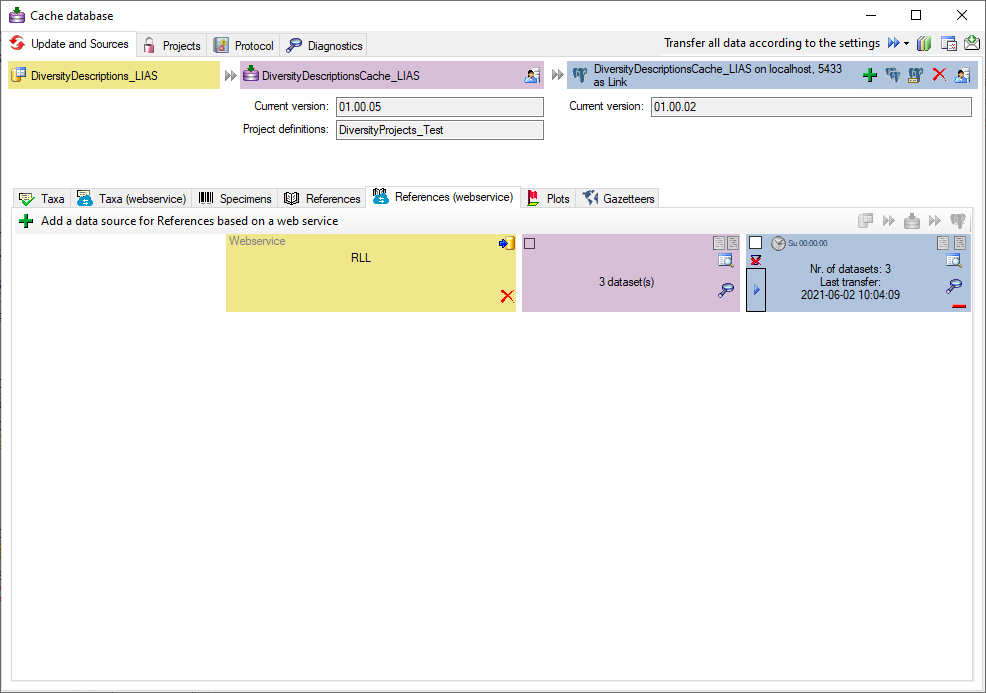
Transfer
To transfer the data of a webservice into the
cache database use the 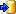 button. A
window a shown below will open where you must select all
projects related to the webservice you
selected. You must transfer the projects into the
cache database before transferring the webservice data! Only
entries found within these projects will be transferred.
button. A
window a shown below will open where you must select all
projects related to the webservice you
selected. You must transfer the projects into the
cache database before transferring the webservice data! Only
entries found within these projects will be transferred.
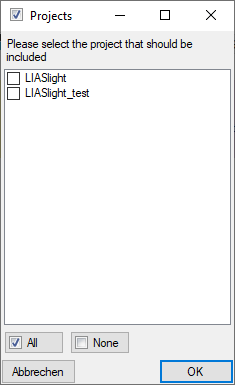
Use the
buttons to inspect the content. Names that are already present will not
be transferred again. So if you need these values to be updated you have
to remove it (see below) and add it again. Links that refer to lists of
names instead of single names will not be inserted. These links will be
stored in the Errorlog to enable their inspection.
To transfer the data into the Postgres database, you have to
connect with a database first. Use the button
to transfer the data from the ** ** cache database into the
Postgres database and the buttons to
inspect the content.
Removal
With the button you can remove the sources
together with the views (see above).
 linked
server. The data of these sources are stored and
transferred independent from the project data. For further details see
chapter Sources from other modules
linked
server. The data of these sources are stored and
transferred independent from the project data. For further details see
chapter Sources from other modules








