Generate Projects

Generate a project data document
This tool is used to generate a structured documentation of project
related data stored in the database. To use this tool, start a query for
projects and choose Data ->
 Generate Document … from the menu. A
window will open as shown below.
Generate Document … from the menu. A
window will open as shown below.
You may select all entries by clicking the  all button, deselect all entries by clicking the
all button, deselect all entries by clicking the
 none button or toggle your selection by
clicking the
none button or toggle your selection by
clicking the  swap button. Choose among
the provided options and click on the button Create … documentation to
create a document in one of the available formats.
swap button. Choose among
the provided options and click on the button Create … documentation to
create a document in one of the available formats.
HTML
If you create a HTML documentation, a local file named <Database
name>_Project.htm is generated in the application directory, that
might be copied and edited for own purposes. By clicking button
 Select colors you may open a dialog window
where you can select the colors of different elements (see window
below).
Select colors you may open a dialog window
where you can select the colors of different elements (see window
below).
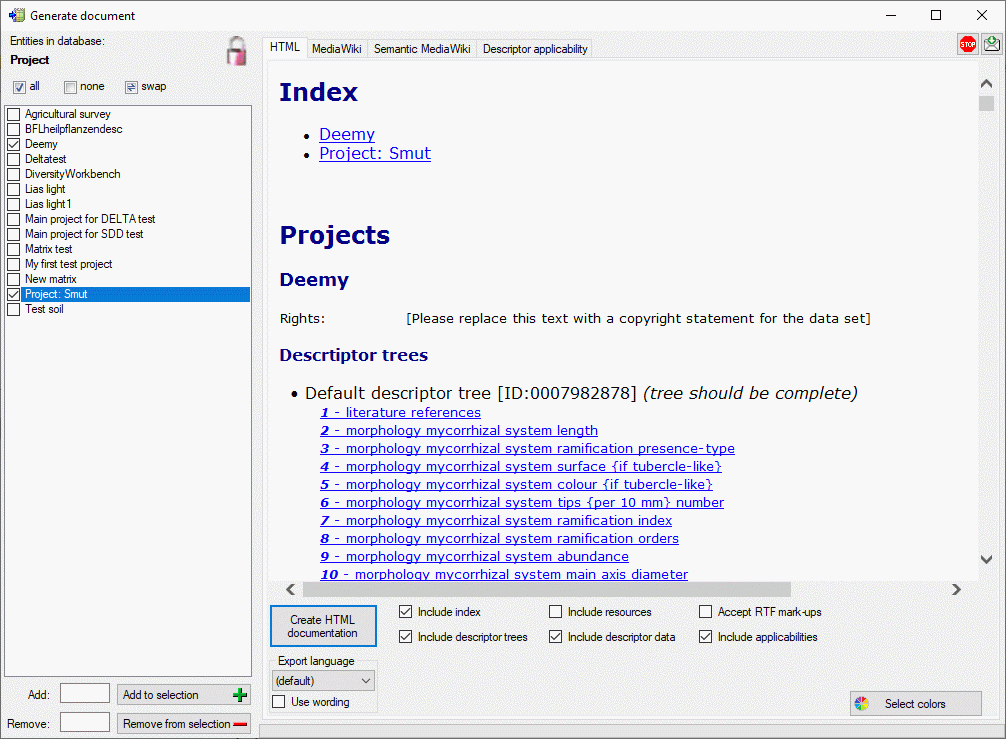
You have the choice to output additional information besides the basic project data by selection the options Include descriptor trees, Include descriptor data or Include applicabilities (see window below).
MediaWiki
If you create a MediaWiki documentation, you may copy the generated text from the output window and insert it in the MediaWiki page. With the Layout option you may determine if all data shall be included in a large table or if several tables with additional header lines shall be generated (see image below).
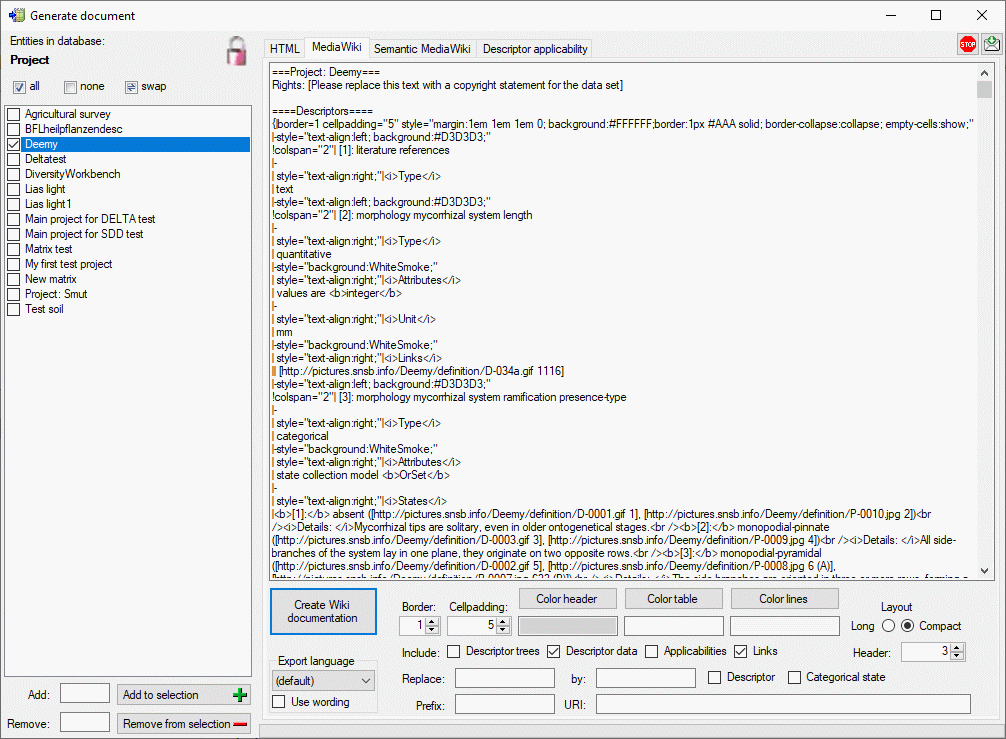
If you specify values in text fields Replace: and by: you can perform text replacements for Descriptor or Categorical state names in the generated output. By specifying a Prefix: for a Semantic MediaWiki (see next section) you can generate lokal links to this kind of Wiki pages. Additionally, you may insert the absolute link adresses by entering the base Wiki address in the URI: filed.
Semantic MediaWiki
If you create a Semantic MediaWiki documentation, the descriptors, categorical states, descriptor trees and descriptor applicability information are generated in a format that fits to terminology platforms as used e.g by TDWG. In this scheme the most important entities are “Concept” and “Collection”. Each “Concept” represents a single descriptor or categorical state value, which is shown on an own page. Each “Collection” represents a single descriptor tree or descriptor tree node, which is shown on an own page. The pages are named according the schema <prefix>:<entity label> [(<number>)], where the <number> parts may be optional, depending on the Naming: setting (see image below):
- If Opt. order (Optional order) is selected the <number> part is omitted if the name is unambigious. Otherwise it starts with 1 for the first duplicate and is increased for each subsequent one to avoid duplicate page names.
- If Order is selected the <number> starts with 1 and is increased for each subsequent duplicate to guarantee unambigious page names.
- If Entity ID is selected the <number> contains the database internal ID of each entry to guarantee unambigious page names.
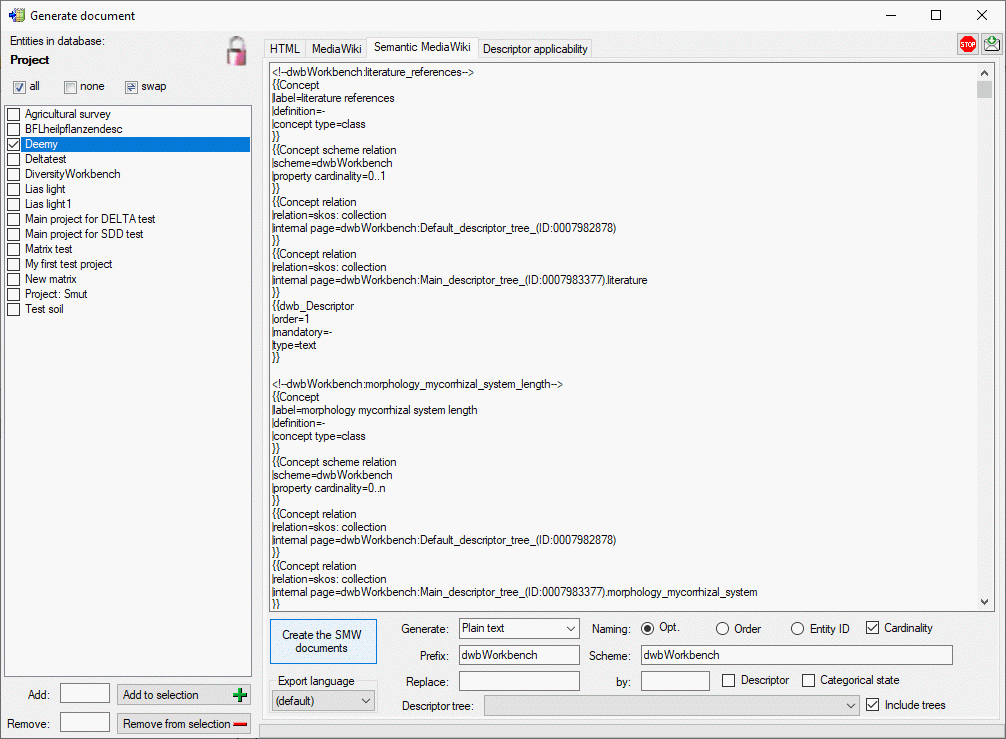
The Cardinality option includes information about multiple occurance and the mandatory property in the descriptor concepts. By selecting the Include trees option the descriptor trees and the tree structure will be included as collections where subordinated tree nodes are represented by concatenated node names, e.g. <prefix>:<Tree name>.<Node 1 name>.<Node 2 name>. If you specify values in text fields Replace: and by: you can perform text replacements for Descriptor or Categorical state names in the generated output.
If Generate: XML for Wiki import is selected, the output is generated in an XML format that may be imported to a semantic media wiki. To show all generated data, the two templates “dwb_Descriptor” and “dwb_CategoricalState” must be inserted in the wiki.
If Generate: XSD/XML document is selected, an XML schema (XSD) is
generated in the main window. If schema generation was ended without
problems, a selection list will be shown where description items for the
XML document may be selected. For the selected descriptions an XML
document structured according the XSD will be shown in a separate
window. By default no descriptions will be exported that include any
descriptor with data status “Data withheld”. This is indicated by the
 button in the upper right corner of the window. You
may click on this button to include those descriptions. The button will
change to
button in the upper right corner of the window. You
may click on this button to include those descriptions. The button will
change to  and only the marked descriptor
summary data will be excluded from the document.
and only the marked descriptor
summary data will be excluded from the document.
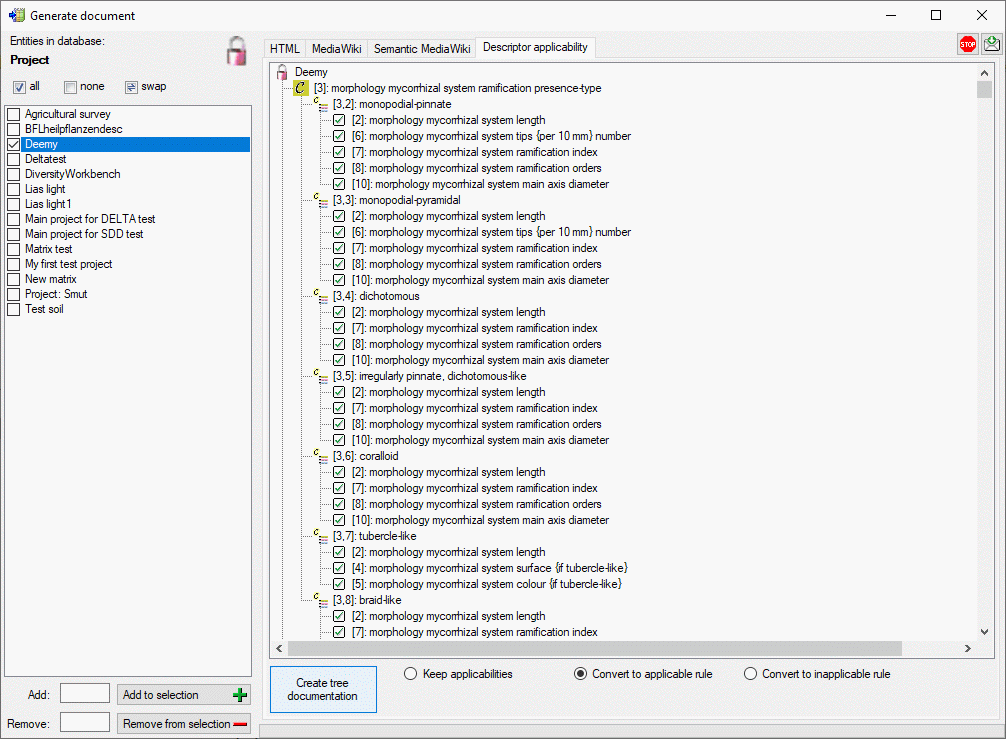
Descriptor applicability
The descriptor applicability tree shows the selected projects
and as subordinated nodes the categorical
descriptors  that control the applicability of
dependent descriptors. Contained in the controlling descriptor are their
categorical states
that control the applicability of
dependent descriptors. Contained in the controlling descriptor are their
categorical states 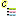 and the dependent
descriptors with the applicability rule “applicable-if”
and the dependent
descriptors with the applicability rule “applicable-if”
 or “inapplicable-if”
or “inapplicable-if”  .
The descriptor names are prefixed with their sequence number in square
brackets, the states with the descriptor’s sequence number and their
own.
.
The descriptor names are prefixed with their sequence number in square
brackets, the states with the descriptor’s sequence number and their
own.
If you create a applicability tree documentation, two local tabulator-separated text files are generated. The first file named <Database name>_ApplicabilityNodes.txt contains the node list with columns “Id”, “Label” and “Modularity class” (“Project”, “Descriptor” or “State”). The second file named <Database name>_ApplicabilityEdges.txt contains the edges list with columns “Source”, “Target” and “Label” (“Includes” for project-descriptor relations, “Contains” for descriptor-state relations or “Applicable” rsp. “Inapplicable” for state-descriptor relations). You may import those files to a graphic program like “Gephi” to visualize the descriptor applicabilities.
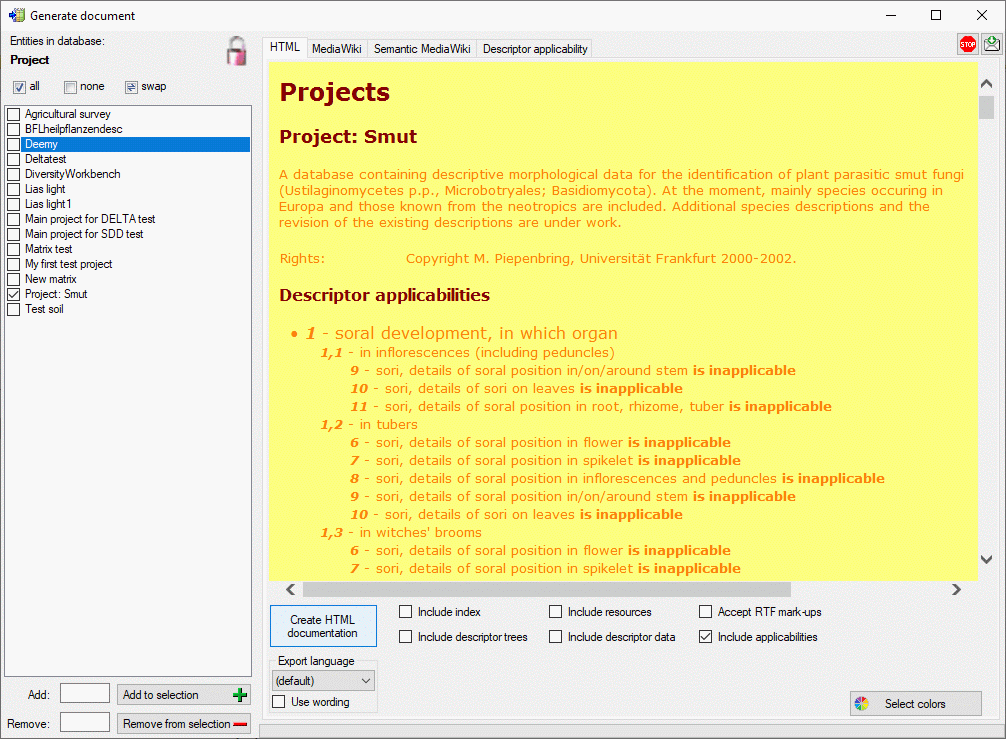
By selecting the option Convert to applicable rule or Convert to inapplicable rule the applicability settings stored in the database can be converted to the required complatible format (see image below).